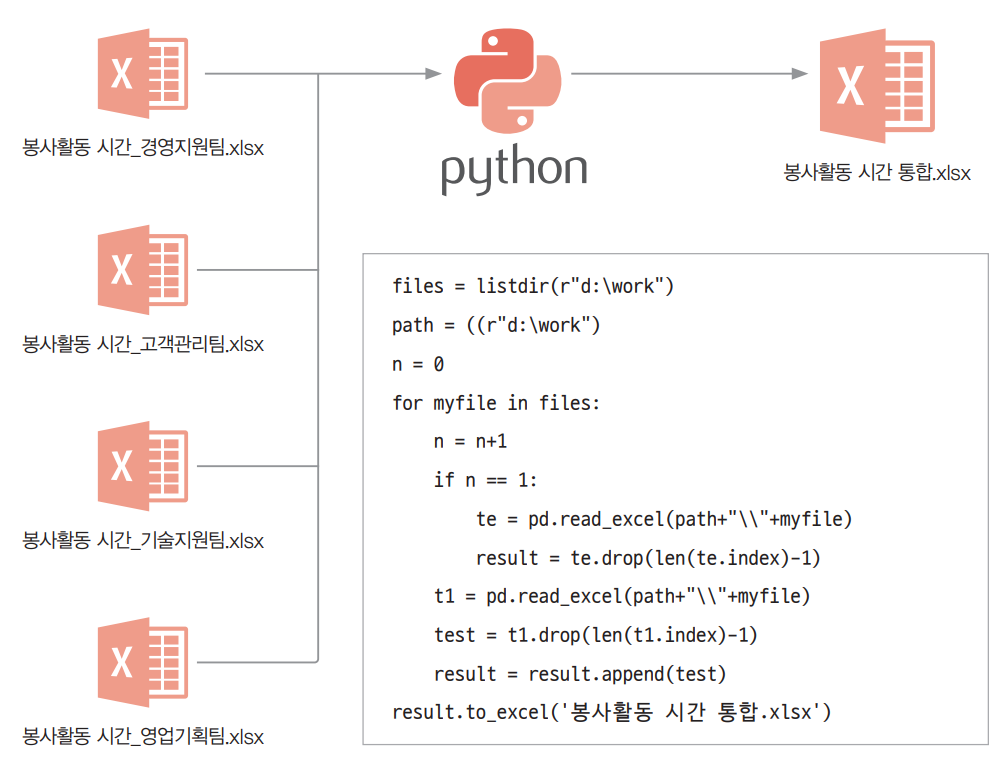
챗GPT는 대규모 텍스트 데이터를 학습하여 프로그래밍 언어의 문법과 코딩 패턴을 이해합니다. 이를 통해 사용자 요청과 문제 해결에 필요한 코드를 생성하고, 오류를 찾아 수정할 수도 있습니다. 챗GPT를 활용해, ‘월마트의 2010년~2022년 주별 판매금액’ 데이터셋으로 각 항목의 상관 관계를 분석하고 시각화하는 코드를 작성해 보겠습니다.
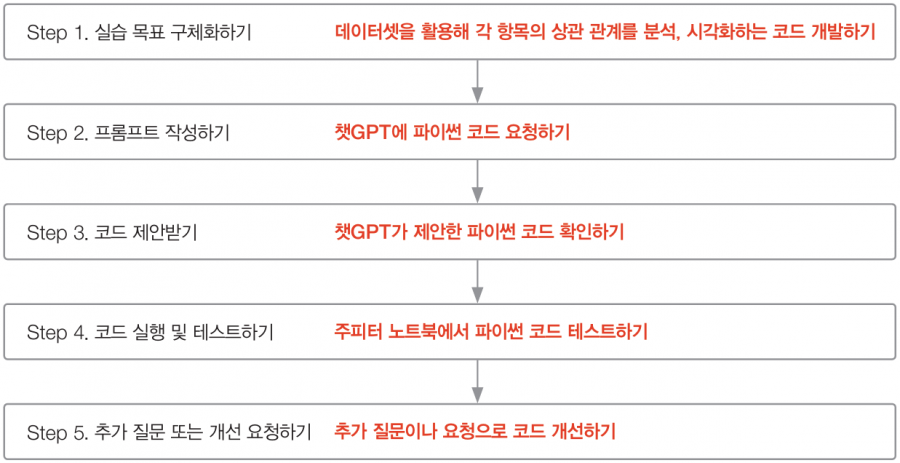
챗GPT를 활용한 파이썬 코딩은 다음과 같은 단계로 진행하면 좋습니다.
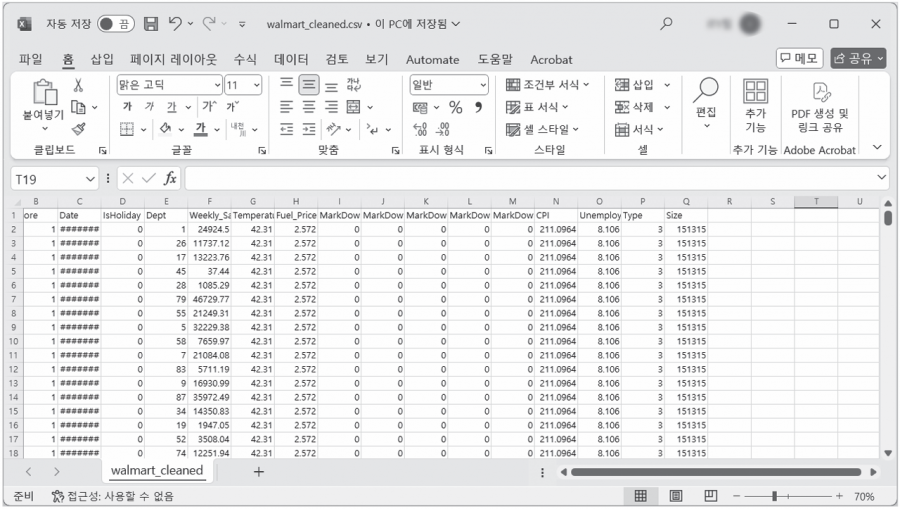
▶ 예제 파일: chapter10 walmart_cleaned.csv
목표를 ‘월마트 판매 데이터 각 항목에 대한 상관 관계를 분석하고 시각화하는 파이썬 코드 개발’로 잡아보겠습니다.
챗GPT에게서 파이썬 코드를 받기 위해 명확한 프롬프트를 작성해야 합니다.
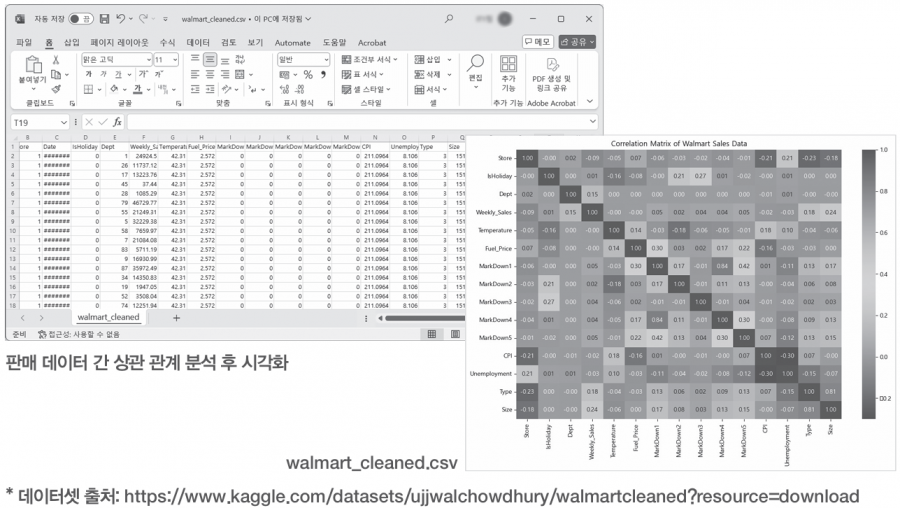
예제 파일: chapter10 > walmart_cleaned.csv 파일을 불러옵니다. 파일의 데이터를 살펴보면 칼럼 정보를 확인할 수 있습니다. 그중에서 상관 관계 분석이 가능한 수치형으로 된 항목을 정리하면 다음 표와 같습니다.
*상관 관계 분석이란 두 변수 간 관계를 측정하고 평가하는 통계 기법입니다. 상관 관계 분석은 주로 수치 데이터를 기반으로 하는데, 이는 상관 관계 분석에서 사용하는 수학적 계산에 수치 데이터가 필요하기 때문입니다.
| 칼럼(항목) | 내용 |
| IsHoliday | 휴일 여부 |
| Dept | 부서 ID |
| Weekly_Sales | 주간 판매액 |
| Temperature | 온도 |
| Fuel_Price | 연료 가격 |
| MarkDown1 | 가격 인하 관련 항목1 |
| MarkDown2 | 가격 인하 관련 항목2 |
| MarkDown3 | 가격 인하 관련 항목3 |
| MarkDown4 | 가격 인하 관련 항목4 |
| MarkDown5 | 가격 인하 관련 항목5 |
| CPI | 소비자 가격 지수 |
| Unemployment | 실업률 |
| Type | 상점 유형 |
| Size | 상점 크기 |
상관 관계를 분석하기 위해 살펴보려는 항목을 포함하여 다음과 같이 프롬프트를 작성하고 챗GPT에게 요청합니다.

챗GPT는 프롬프트 내용에 맞춰 다음과 같은 파이썬 코드를 제안해 줍니다. 물론 같은 내용을 요청하더라도 챗GPT가 제안하는 코드 내용은 조금씩 다를 수 있습니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터셋 불러오기
data = pd.read_csv('walmart_cleaned.csv')
# 분석할 칼럼 설정
columns_to_analyze = [
'Store', 'IsHoliday', 'Dept', 'Weekly_Sales', 'Temperature',
'Fuel_Price', 'MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4',
'MarkDown5', 'CPI', 'Unemployment', 'Type', 'Size'
]
# 필요한 칼럼만 추출
data = data[columns_to_analyze]
# 카테고리형 변수 'Type'을 수치형으로 변환
data['Type'] = data['Type'].astype('category').cat.codes
# 상관 계수 계산
correlation_matrix = data.corr()
# 상관 관계 히트맵 시각화
plt.figure(figsize=(15, 10))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm',
linewidths=0.5)
plt.title('Correlation Matrix of Walmart Sales Data')
plt.show()
다음과 같은 과정을 수행하는 코드를 제안 받았습니다.
1. 데이터셋을 불러옵니다.
2. 분석할 칼럼을 선택합니다.
4. 각 칼럼 간 상관 계수를 계산합니다.
3. (상관 계수 계산을 위해) ‘Type’ 칼럼을 수치형으로 변환합니다.
5. 히트맵을 사용해 상관 관계를 시각화합니다.
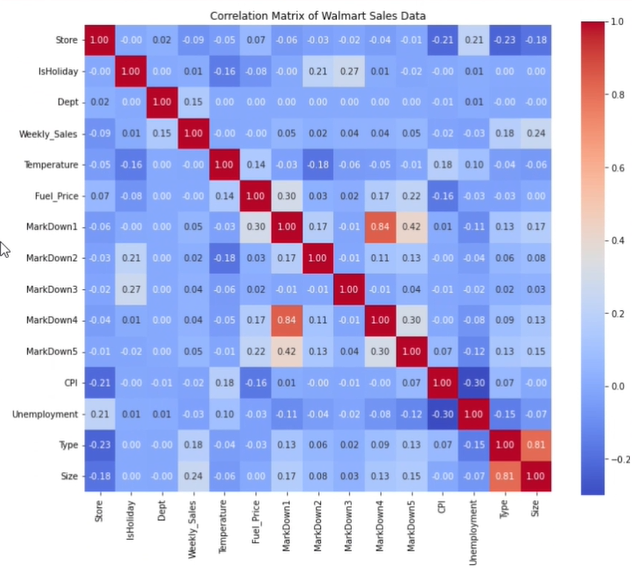
이 코드를 실행하면 주어진 데이터셋의 각 항목 간 상관 관계를 한눈에 확인할 수 있습니다.
주피터 노트북에서 챗GPT가 제안한 코드를 실행하여 결과를 확인합니다. 필요하다면 추가로 질문하거나 개선할 점을 요청해 보세요. 이 과정을 반복하여 더 구체적인 코드를 개발할 수 있습니다.
챗GPT가 제시한 코드가 에러 없이 완벽히 작동한다는 보장은 없습니다. 제시한 코드에 오류가 있을 수 있으며, 필요한 패키지가 PC에 설치되어 있지 않아서 에러 화면을 마주하게 될 수도 있습니다. 이 경우 챗GPT에게 출력된 에러 메시지와 함께 해결 방법을 알려 달라고 추가로 요청하면 문제를 해결할 수 있습니다.
위 콘텐츠는 『일잘러의 비밀, 엑셀 대신 파이썬으로 업무 자동화하기(개정판)』의 내용을 재구성하여 작성하였습니다.

최신 콘텐츠