2025학년도 수능 국어 지문으로 등장해 화제가 된 디퓨전 모델. 생소한 개념에 많은 수험생들이 당황했지만, 사실 이는 우리 일상에서 쉽게 만나볼 수 있는 AI 기술입니다. 'DALL-E2'나 '미드저니'와 같이 놀라운 이미지를 만들어내는 AI의 핵심에 바로 이 디퓨전 모델이 있죠. 얼핏 복잡해 보이는 원리도 차근차근 살펴보면 꽤 흥미롭고 명쾌하답니다.
디퓨전diffusion 모델은 생성적 적대 신경망보다 훈련 과정이 안정적이고 비교적 구현이 쉽습니다. 최근 몇 년 사이, 품질 면에서도 생성적 적대 신경망을 뛰어 넘으며 이미지 생성 분야의 판도를 완전히 바꿔 놓았죠.
* 영단어 diffusion은 확산이라는 뜻으로, 액체나 기체에 다른 물질이 섞여서 점차 번져 가는 현상을 의미합니다. 디퓨전 모델을 확산 모델이라고 부르기도 합니다.
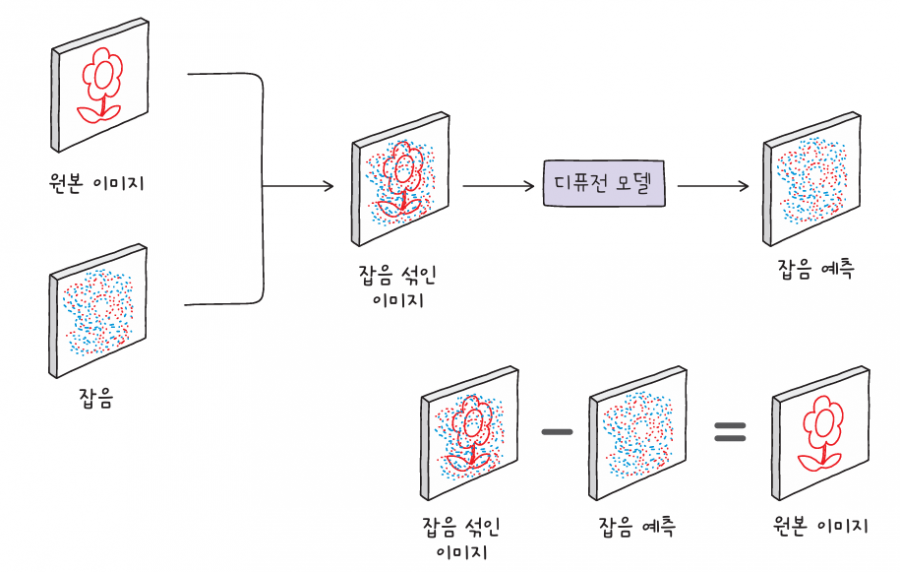
디퓨전 모델의 훈련 목표는 이미지에 섞인 잡음noise을 예측하고, 잡음을 제거해서 원본 이미지를 복원하는 것입니다. 먼저 원본 이미지에 잡음을 섞습니다. 마치 사진에 마구 낙서를 하는 것처럼 원본 이미지의 세부 사항을 알아볼 수 없게 만드는 것입니다. 디퓨전 모델은 이렇게 잡음이 섞인 이미지를 입력으로 받습니다. 모델이 잡음 섞인 이미지에서 원본과 더 가까운 결과물을 생성할수록 성공적인 훈련이라고 할 수 있죠.
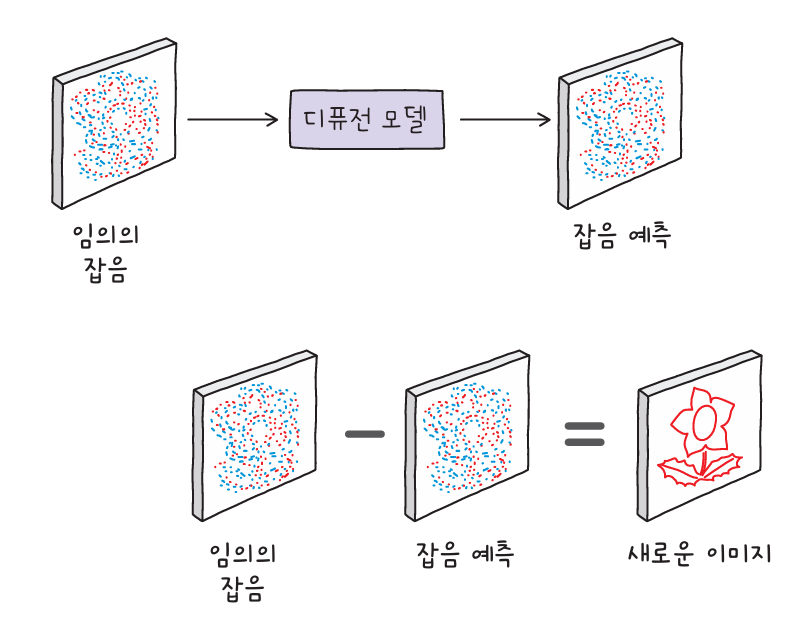
이제 훈련이 끝난 디퓨전 모델에 임의의 잡음을 입력합니다. 디퓨전 모델은 입력 이미지에서 잡음의 패턴을 예측합니다. 그리고 잡음을 점진적으로 제거하면 학습에 사용한 이미지가 아닌 완전히 새로운 이미지를 만들 수 있습니다.
다음은 디퓨전 모델로 생성한 이미지입니다.

2021년, 오픈AI는 텍스트로부터 이미지를 생성하는 인공지능 DALL·E를 공개했습니다. 당시에도 이목을 끌었지만, 1년 뒤인 2022년 공개된 DALL·E2가 디퓨전 모델을 사용하자 다른 이미지 생성 모델들도 앞다투어 디퓨전을 채택하기 시작했습니다. DALL·E2의 동작 방식을 살펴보겠습니다.
DALL·E2는 텍스트 인코더와 프라이어prior, 그리고 디코더로 구성됩니다. 먼저, 텍스트 인코더는 프롬프트를 입력받아 텍스트 임베딩을 생성하고, 텍스트임베딩은 프라이어의 입력으로 사용되어 이미지 임베딩을 생성합니다. 마지막으로, 디코더 모델이 임베딩으로부터 실제 이미지를 생성합니다.
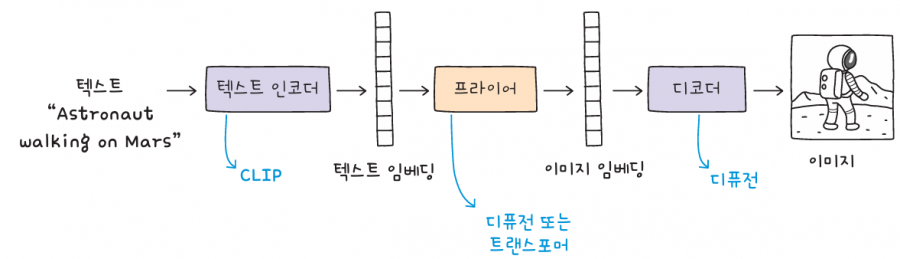
DALL·E2의 텍스트 인코더는 오픈AI가 개발한 또 다른 신경망 모델인 CLIPContrastive Language-Image Pre-training을 사용합니다. CLIP은 이미지와 이미지를 설명하는 텍스트를 쌍으로 연결하도록 훈련한 모델입니다. 이미지와 텍스트를 각각 임베딩으로 변환한 후 이미지 임베딩에 가까운 텍스트 임베딩을 찾거나 그 반대의 작업을 수행합니다.
프라이어는 디퓨전 또는 트랜스포머를 사용합니다. CLIP의 이미지와 텍스트 임베딩 쌍을 사용하여 훈련한 다음, 텍스트 임베딩을 이미지 임베딩으로 변환하는 역할이죠.
마지막으로 디코더가 디퓨전 모델을 사용하여 이미지 임베딩으로부터 이미지를 생성합니다.
오픈AI의 DALL·E2가 이미지를 생성하는 원리에 대해 살펴보았습니다. 디퓨전은 생성적 적대 신경망보다는 안정적인 모델이지만, 종종 잡음을 완전히 제거하지 못해서 불완전한 이미지를 생성하기도 합니다. 이러한 문제를 해결하고 모델을 더 안정적으로 보완한 최신 디퓨전 모델의 작동 방식을 알아보겠습니다.
2022년, 스태빌리티 AIStability AI는 디퓨전을 개선한 모델인 스테이블 디퓨전stable diffusion을 발표했습니다. 훈련 과정이 안정화되고, 속도도 디퓨전에 비해 크게 향상되었죠. 잡음을 완전히 제거하지 못했던 기존의 문제도 스테이블 디퓨전에서는 오토인코더를 활용하여 해결했습니다.
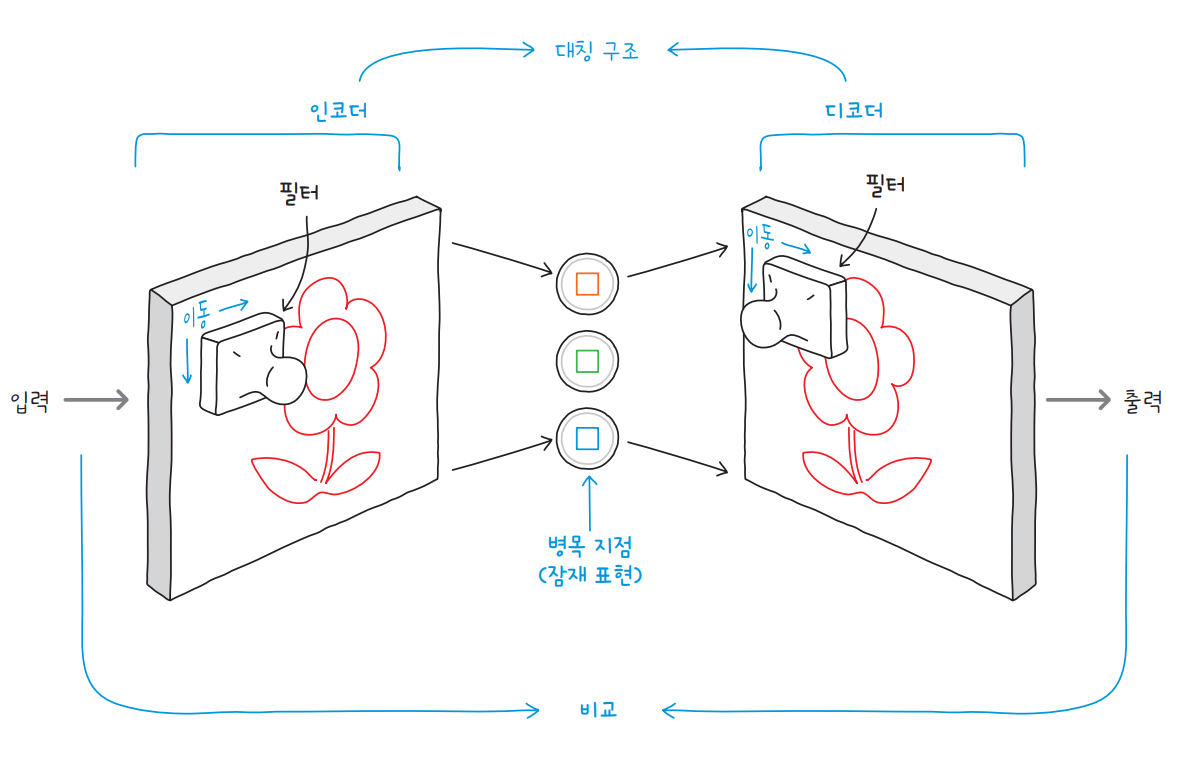
스테이블 디퓨전은 마치 디퓨전 모델을 오토인코더로 감싸 놓은 듯한 구조입니다. 이를 바꾸어 말하면 디퓨전 과정이 전체 이미지를 대상으로 수행되는 것이 아니라 오토인코더가 만든 잠재 표현에서 수행된다는 것입니다.
먼저 오토인코더의 인코더가 원본 이미지를 잠재 표현으로 압축합니다. 그다음 디퓨전 모델이 잠재 표현에 잡음을 추가하고, 잡음이 섞인 잠재 표현으로부터 잡음을 제거하며 훈련합니다. 이 과정에서 CLIP이 생성한 텍스트 임베딩이 오토인코더의 인코더에 입력으로 전달됩니다. 디퓨전 모델이 잠재 표현에서 잡음을 제거하면, 오토인코더의 디코더를 통해 새로운 이미지를 생성할 수 있습니다.
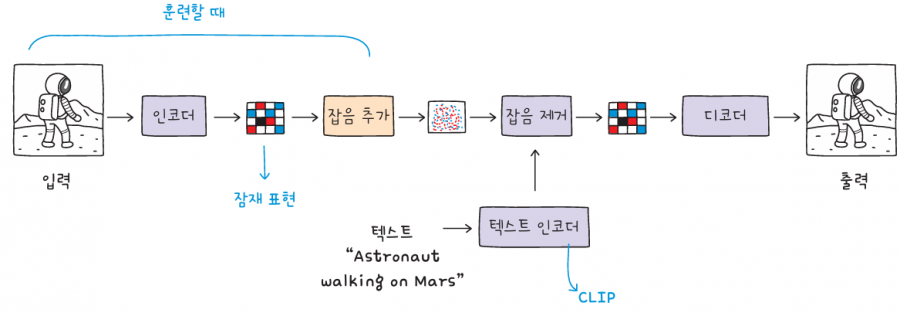
이러한 이미지 생성 훈련을 거치면, 스테이블 디퓨전은 임의의 잡음과 텍스트 임베딩만으로 새로운 이미지를 생성할 수 있습니다. 디퓨전 모델이 잡음을 제거하고 오토인코더의 디코더가 이미지를 완성하는 것이죠.
이미지 생성 인공지능인 미드저니가 스테이블 디퓨전 모델을 사용합니다. 스테이블 디퓨전은 오픈 소스입니다. 개발에 필요한 소스 코드를 누구나 열람할 수 있으며, 덕분에 스테이블 디퓨전을 기반으로 하는 이미지 생성 인공지능이 계속 생겨나고 있습니다. 이미지 생성 모델을 사용하는 서비스가 생겨날수록 이미지 생성 인공지능은 더욱 발전하고 정교해질 것입니다.
위 컨텐츠는 『인공지능 전문가가 알려 주는 챗GPT로 대화하는 기술』의 내용을 재구성하여 작성되었습니다.
디퓨전 모델의 수학적 원리가 궁금하거나 기초부터 직접 구현해보고 싶으신 분은
『밑바닥부터 시작하는 딥러닝 5』를 참고해 주세요.


최신 콘텐츠