이 글에서는 Uber와 같은 택시 애플리케이션 서비스의 아키텍처 및 시스템 설계에 대해 배워보고자 합니다. Uber 애플리케이션에서 탑승자(CAB를 원하는 사람)가 앱에서 드라이버를 요청하면 해당 사용자를 선택하기 위해 드라이버가 이동합니다. 이면에는 여행을 지원하는 1,000대의 서버가 있으며 여행에 테라바이트의 데이터가 사용되었습니다. Uber 회사가 시작되었을 때 그들은 단순한 모놀리식(monolithic) 아키텍처를 가졌습니다. 백엔드 서비스, 프런트 엔드 서비스 및 데이터베이스가 있었습니다. 처음에는 애플리케이션 서버에 Python을 사용했습니다. 그들은 비동기 작업을 위해 Python 기반 프레임 워크를 사용했습니다.
2014년 이후 Uber의 아키텍처는 서비스 지향 아키텍처(service-oriented architecture)로 발전했습니다. Uber는 택시와 음식, 화물 서비스도 하고 있습니다. 모든 것이 하나의 시스템에 만들어져있었습니다. 택시 관련 플랫폼의 어려운 점은 수요에 대한 공급 또는 공급에 대한 수요를 충족시키는 것입니다. Uber 백엔드의 주요 임무는 모바일 트래픽을 처리하는 것입니다. 왜냐하면 휴대폰이 없다면 이런 서비스를 운영하는 것은 매우 어렵기 때문입니다. 모든 게 GPS로 작동하기 때문이죠. Uber 시스템은 탑승자와 택시를 연결하는 실시간 마켓 플레이스 같은 것입니다. 즉, 아키텍처에 서로 다른 두 가지 서비스가 필요합니다.
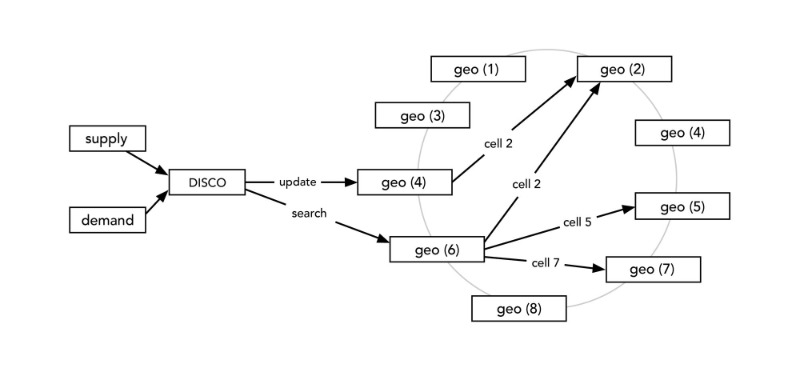
DISCO (Dispatch Optimization)
디스패치 최적화
이 디스패치 시스템의 작동 방식에 대해 이야기해 보겠습니다. 디스패치 시스템은 지도 및 위치 데이터 기반 위에서 완벽하게 작동합니다. 즉, 위치 데이터를 모델링하고 적절하게 지도를 만들어야 했습니다. 위도 및 경도 데이터를 사용하여 위치를 요약하고 근사화하는 것은 매우 어렵습니다. 이 문제를 해결하기 위해 Uber는 Google S2 라이브러리를 사용했습니다.
Google S2 지오메트리 라이브러리란?
S2 라이브러리의 독특한 특징은 데이터를 평면 2차원 투영(아틀라스 유사)으로 나타내는 기존의 지리 정보 시스템과 달리 S2 라이브러리는 모든 데이터를 3차원 구체(지구와 유사) 위에 표시한다는 것입니다. 이를 통해 이음새 나 특이점 없이 단일 좌표계를 사용하고 지구의 실제 모양에 비해 왜곡이 적은 전 세계 지리 데이터베이스를 구축 할 수 있습니다. 지구는 구형이 아니지만, 평평한 것보다 구형에 훨씬 더 가깝습니다!
S2 기능들
라이브러리의 주목할 만한 기능은 다음과 같습니다.
s2geometry 공식 사이트 - https://s2geometry.io/about/overview
이 라이브러리는 구형 지도 데이터를 가져와서 이 데이터를 작은 셀 (예 : 1km x 1km 셀)로 결정합니다. 이 셀을 결합하면 완전한 지도를 얻을 수 있습니다. 각 셀에는 고유 한 ID가 있으며, 이것은 분산 방식(distributed manner)으로 데이터를 저장하는 가장 쉬운 방법입니다. 서버에서 위치 데이터를 가져오려면 이 셀의 ID만 있으면 됩니다 (컨시턴트 해싱을 사용하여 데이터를 저장할 수 있음).
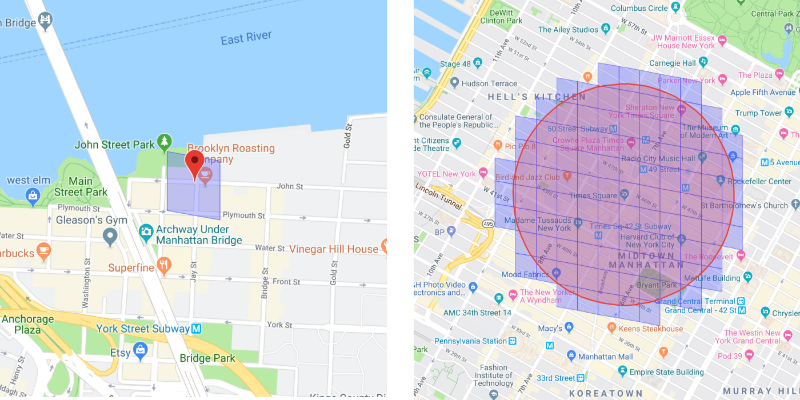
또한 S2 라이브러리는 주어진 셀의 범위를 제공합니다. 예를 들어 지도에 그려진 원을 원하고 원 안에 있는 모든 공급자(드라이버)를 파악하고 싶다고 가정해 보겠습니다. 우리가 해야 할 일은 S2 라이브러리를 사용하고 반경을 지정하는 것입니다. 따라서 특정 원에 기여하는 모든 셀을 자동으로 필터링합니다. 그렇게 하면 모든 셀 ID를 알 수 있습니다. 이제 우리가 필요로 하는 데이터와 해당 셀에 속한 데이터를 쉽게 필터링할 수 있습니다. 그런 식으로 모든 셀에서 사용 가능한 공급자 리스트(드라이버)을 확보하고 ETA(Estimated time of travel- 여행 예측 시간)를 계산할 수 있습니다.
탑승자(Rider)와 운전자(Driver)를 언제 매칭해야 할까요?
탑승자(Rider)의 위치에서 반경 2 ~ 3km 떨어진 원을 그립니다. 그리고 S2 라이브러리를 사용하여 사용 가능한 모든 운전자(Driver)를 나열합니다. 이제 ETA (여행 예측 시간)를 확인해야 합니다. 여기서 최단 거리 (Euclidean Distance)를 사용할 수 있습니다. 하지만 이것이 ETA (여행 예측 시간)를 정확하게 제공하지는 않습니다. A에서 B까지 직접 선을 그릴 수는 없습니다. 경로는 예상보다 길 수 있습니다. 당신은 연결된 도로로만 갈수 있기 때문입니다.
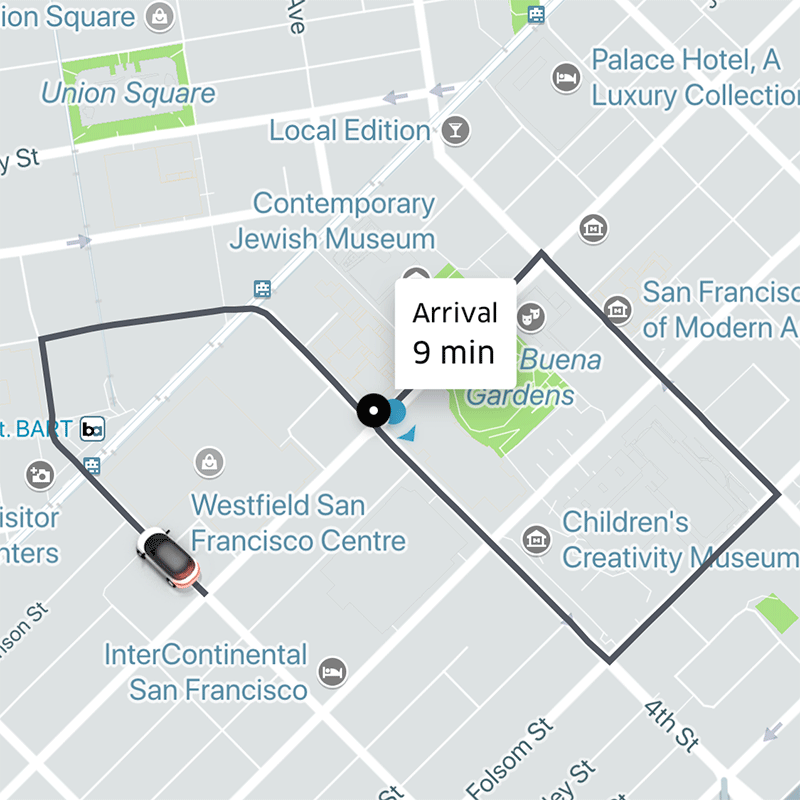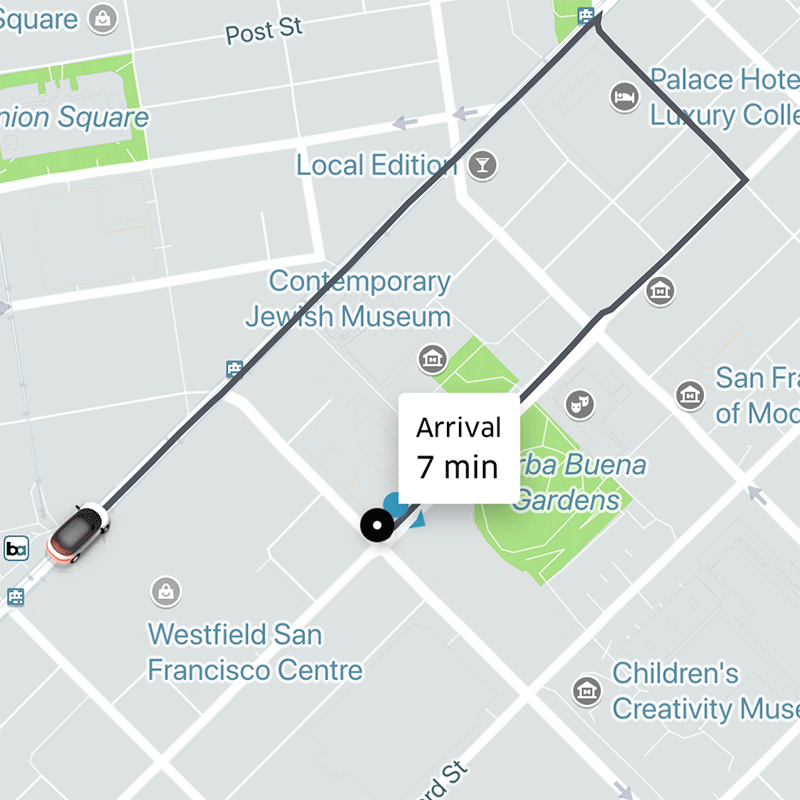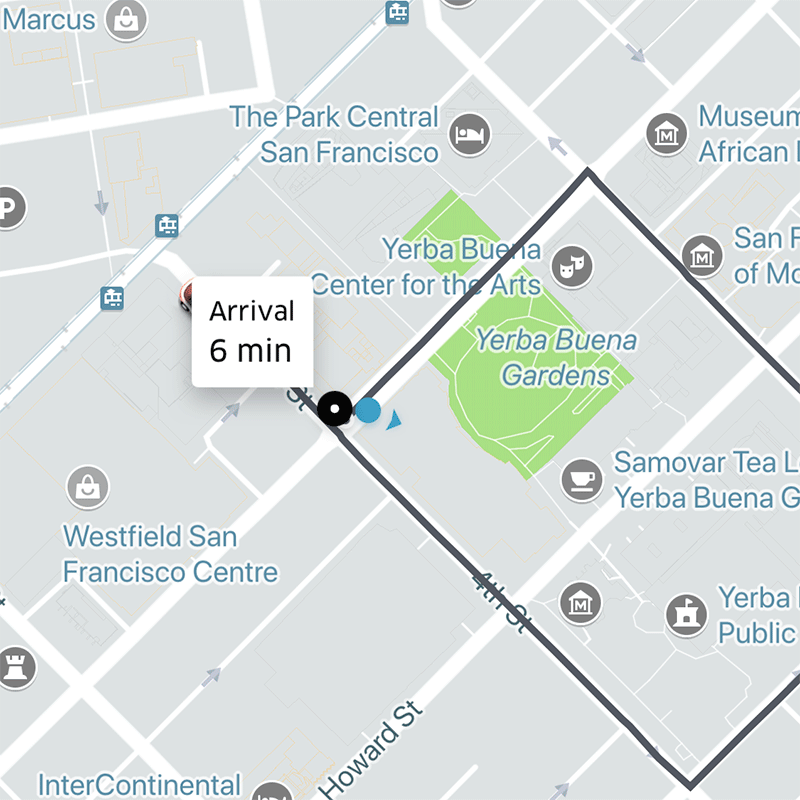
이제 필터링 된 모든 운전자의 최대 거리를 알 수 있습니다. 동시에 운전자에게 알림을 보낼 수 있습니다. 운전자가 수락하면 운전자와 탑승자를 연결할 수 있습니다.
System Design (시스템 설계)
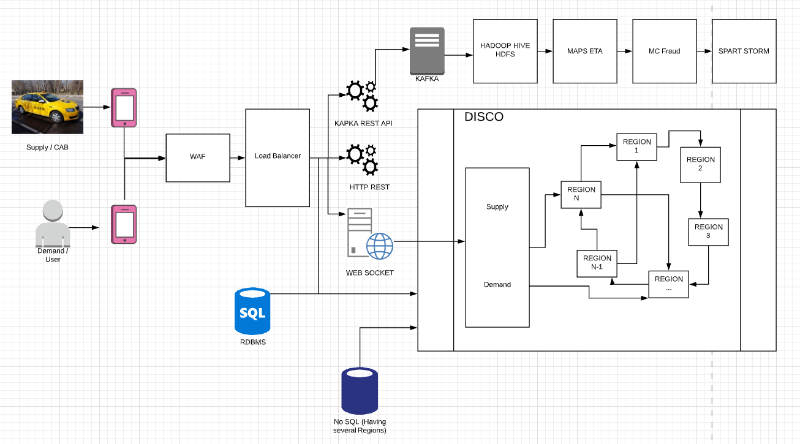
diagram 1
위 다이어그램에서 CAB는 CAB(운전자)를 의미하는 공급이고 User는 사용자가 드라이버를 요청하는 수요(Demand)입니다. CAB들이 4 초마다 위치 데이터를 KAFKA REST API로 전송합니다. 모든 호출(call)은 방화벽을 관통하여 발생합니다. 그런 다음 Load Balancer로 이동하고, KAPKA로 이동하여 다른 서버로 이동합니다. 또한 위치 데이터 사본이 데이터베이스로 전송되고, DISCO(Dispatch Optimization)도 Cab의 최신 위치를 유지합니다.
WAF (Web Application Firewall) — 보안 목적으로 사용합니다. 여기에서 차단된 IP, 봇 및 Uber에서 지원하지 않는 지역의 요청을 차단할 수 있습니다.
Load Balancer(로드 밸런서) — 여기서는 레이어 3, 레이어 4 및 레이어 7과 같은 다른 로드 밸런서 레이어를 사용할 수 있습니다. 레이어 3은 IP 기반 로드 밸런서를 기반으로 작동합니다 (트래픽의 모든 IP는 레이어 3 로드 밸런서로 이동합니다. 레이어 4에서는 DNS 기반의 로드 발랜싱을 사용할 수 있습니다. Layer7에서는 어플리케이션 레벨의 로드 발랜싱 기반으로 작동합니다.)
KAPKA REST API — 모든 Cab에 대한 모든 위치 데이터를 사용할 수 있는 엔드 포인트를 제공합니다. 예 : 한 도시에 대해 1000 개의 택시가 운영되고 있으며 4 초마다 위치를 전송합니다. 즉, 4 초마다 KAPKA REST API에 대해 1000 개의 위치가 전송되었음을 의미합니다. 이러한 위치는 Alive 상태를 유지하기 위해 DISCO로 전송됩니다.
WEB SOKET — 일반적인 HTTP 요청이 아니라면 웹 소켓은 이러한 종류의 응용 프로그램에 정말 도움이 됩니다. 클라이언트에서 서버로 메시지를 보내고 서버에서 클라이언트로 메시지를 보내는 동기화 방식을 사용해야 하기 때문입니다. Cab 애플리케이션에서 서버로 또는 사용자와 서버 사이에 연결이 설정되어 있어야합니다. 웹 소켓은 모든 Uber 애플리케이션에 대한 연결을 유지하고 DISCO 또는 서버의 구성 요소에서 발생하는 변경 사항을 중심으로(based on the changes) 애플리케이션과 서버간에 데이터가 교환됩니다. 주로 NodeJS (비동기 및 이벤트 중심 프레임 워크)로 작성되었습니다.
DISCO 컴포넌트
디스패치 시스템은 주로 NodeJS로 작성되었습니다. 따라서 해당 서버는 원할 때마다 응용 프로그램에 메시지를 전송하거나 푸시(send/push) 할 수 있습니다.
우리는 어떻게 DISCO 서버를 확장해야 할까요?
Uber는 DISCO를 확장하기 위해 REPOP라는 것을 사용했습니다. 2가지 기능이 있습니다.
또한 서버가 다른 서버의 책임을 알 수 있도록 도와주는 SWIM 프로토콜/Gossip 프로토콜을 사용합니다. (Gossip 프로토콜에 대해 설명한 글) 이 프로토콜을 사용하면 링에서 하나의 서버를 쉽게 추가하거나 제거할 수 있습니다.
서버를 추가하면 새로 추가된 서버에 책임이 분산되고, 책임을 제거하면 남아있는 다른 서버에 대한 책임이 추가됩니다. (딱 맞는 자료는 아니나 위 문장의 개념은 Jonic님의 HASH-Consistent 글을 통해서 어느정도 이해하실수 있습니다)
사용자가 운전자(드라이버)를 요청할 때 어떻게 동작합니까?
사용자가 Rid(승차)를 요청하면 요청이 웹 소켓에 도착합니다. Web Socket은 요청을 Demand Service(공급 서비스)에 넘깁니다. 그런 다음 Demand Service는 CAB(운전자) 또는 Ride의 요구 사항을 알고 있습니다. 그런 다음 Ride 서비스에 대한 Demand Service 요청에 라이드 정보 (어떤 라이드 유형, 필요한 라이드 수, 위치 정보)가 포함됩니다. Demand Service는 이제 사용자 (라이더)의 위치 (셀 ID)를 알고 서버 링에 있는 서버 중 하나를 요청합니다. Consistent Hashing에서 우리는 책임을 균등하게 분배했습니다. 이렇게 모든 위치 데이터는 아래 이미지 (파란색)와 같이 서버 간에 균등하게 분산되어 있습니다. 공급 서비스는 이제 ETA 값을 계산하여 서버에서 Rider(탑승자)에 가까운 CABS(운전자)를 파악하려고 합니다. 그리고 ETA 값을 계산한 후 Demand (공급) 서버 서버는 WEB SOCKET을 통해 CABS에 "이 라이더가 이 장소에 가고 싶어 하는데 받아줄 수 있나요?”라고 알려줍니다.
만약 운전자가 해당 특정 라이더 및 운전자에게 할당된 여행 요청을 수락하는 경우,
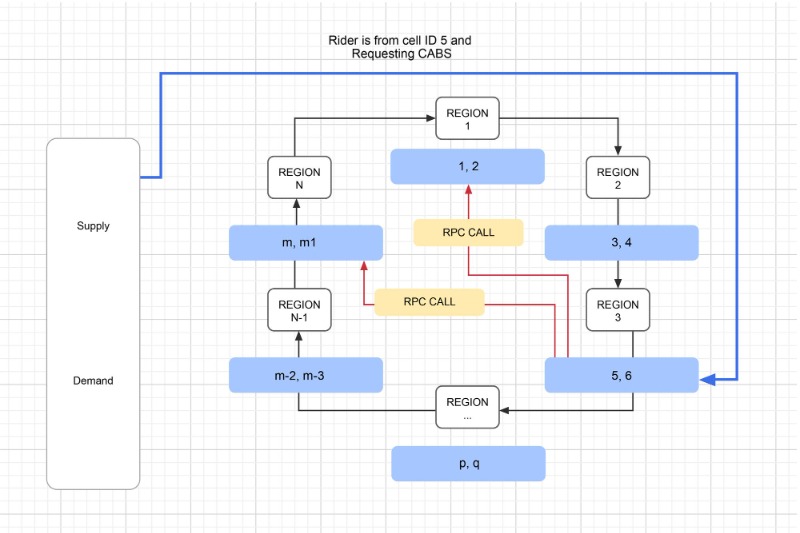
N개의 서버가 있고 이들 서버 사이에 분산된 m개의 위치 셀이 있다고 가정합니다(여기서는 2개의 위치 데이터가 있고 각 서버에 있다고 가정). 라이더가 위치 셀“5”에서 요청합니다. 그런 다음 서버 Region 3은 사용 가능한 CABS를 찾고, 사용 가능한 cab에 대한 ETA 값을 가져와서 해당 데이터를 Supply Server로 전달합니다. 사용할 수 있는 CABS Supply Server (운전자 공급 서버)가 없는 경우 특정 반경의 원을 그려 Rider(탑승자)에 가까운 다음 위치 데이터를 가져옵니다. 그러면 위치 셀 ID가 "2"와 "m"이라고 가정합니다. 그런 다음 서버 Region 3은 Region 1, Region N을 RPC (리모트 프로시져 콜) 호출하여 사용 가능한 CABS를 확인합니다. ETA 값을 계산한 후 모든 데이터가 공급 서버로 전송됩니다.
다음은 Uber 요청을 성공적으로 수행하기 위해 따르는 단계들입니다.
DISCO는 어떻게 더 많은 트래픽을 처리할까요?
Uber가 시스템에 새로운 도시를 추가한다고 가정해봅시다. 그러면 새로 추가된 도시의 교통은 어떻게 처리할 수 있을까요? DISCO ring pop에 새 서버를 추가해야 합니다. 이제 새로 추가된 서버들의 역할(server’s responsibilities)들은 알 수 없습니다.
[1]MAPS ETA 컴포넌트(다이어그램 1)는 ID를 알리고자 하는 새로 추가된 모든 서버를 알고 있습니다. 그리고 (새로 추가된 서버 주위에 있는) 새롭게 추가된 셀들에 기반하고 있다는 것도 알고 있습니다.
DISCO에서 서버를 제거 할 때 무슨 일이 일어나나요??
링에서 서버를 제거하면 모든 셀 ID를 재편성(reshuffles)하고, 기존 서버들에게 변경된 ID를 배포합니다.
우버의 지리-공간 디자인(Geo-Spatial Design)이란?
Uber가 Google S2 라이브러리를 사용하여 Google 지도를 특정 셀로 분류하는 방법을 알고 있으며 이는 Riders(탑승자) 위치에 가장 가까운 CABS(택시-운전자) 위치를 식별하는 데 사용됩니다.
사용자는 (지도를 표현하기 위해) Google 지도를 사용합니다. Google은 이전에 Google 가격 책정 전략 때문에 Map Box를 사용했습니다. 하지만 이제 Uber가 Google API 및 지도로 돌아왔습니다. 이제 Uber는 Google 지도 프레임 워크를 사용하여 앱에 지도를 표시하고, 두 지점 사이의 ETA를 계산하는 데 사용하고 있으며, 경로를 구축하 는데 사용하고, CABS(택시-운전자)와 Riders(탑승자)의 실시간 위치를 계산하여 얻어옵니다.
아시다시피, 당신이 큰 빌딩에 있거나 우버가 지금 갈수 있는 특정 공간에 있다면.
Uber는 입구 및 출구 지점과 같은 선호하는 액세스 포인트 (Preferred Access Points) 를 보여줍니다. 출입문 근처에 정차하는 운전자 택시(Drivers Cabs)로부터 반복적으로 학습한다.
이런 학습을 하기 때문에, 입구와 출구에서만 픽업할 수있는 고객들에게 선호하는 엑세스 포인트를 자동으로 보여줍니다. Uber는 여러 알고리즘과 머신 러닝을 사용하여 선호하는 액세스 포인트를 파악합니다.
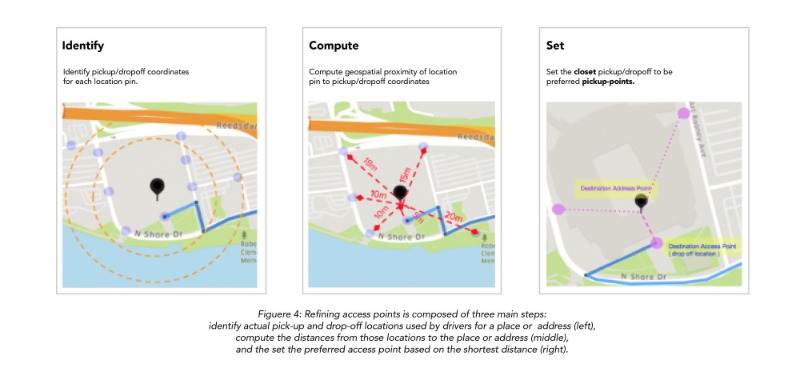
액세스 포인트 개선은 세 가지 주요 단계로 구성됩니다. 운전자가 장소 또는 주소에 대해 사용하는 실제 픽업 및 하차 위치를 식별하고 (왼쪽), 해당 위치에서 해당 위치 또는 주소 (가운데)까지의 거리를 계산한 다음, 설정 최단 거리를 기준으로 선호하는 액세스 포인트 (오른쪽)를 설정합니다.
어떻게 ETA(Estimated time of travel- 여행 예측 시간)를 계산할까요?
여행이 시작되기 전에 앱에서 Driver(운전자)가 픽업 위치에 도착해야 하는 시간을 나타내는 ETA(여행 예측 시간)를 제공합니다.
여행이 시작된 후 앱은 목적지에 도착해야 하는 시간에 대한 ETA(여행 예측 시간)를 제공합니다.
ETA(여행 예측 시간) 시간은 추정치이며 보장되지 않습니다. 교통 체증이나 도로 공사와 같은 다양한 외부 요인이 이동 시간에 영향을 미칠 수 있습니다.
탑승을 요청하기 전에 앱은 검은색 SET PIKPINK LOCITION 막대에 시간을 표시합니다. 이 시간은 가까운 운전자가 픽업 장소에 도착하는 데 걸리는 시간을 추정합니다.
화면 하단의 슬라이더를 사용하여 도시에서 사용 가능한 각 차량 옵션에 대한 ETA(여행 예측 시간)를 볼 수 있습니다. 여행이 시작된 후, 앱은 목적지의 ETA(여행 예측 시간)를 지속적으로 업데이트합니다.
추가로 읽을거리 - Uber 승차 공유 : 비슷한 대기시간을 가지게 하는 매칭 방법 설명
Uber가 사용한 데이터베이스는 무엇일까요?
이전에는 RDBMS를 사용하여 프로필 관련 데이터와 GPS 지점 및 모든 것을 저장했습니다. 그러나 Uber는 도시뿐만 아니라 사용자가 점점 더 많아지면 확장 할 수 없다는 것을 확인했습니다. 그래서 Uber는 스키마가 없는 MYSQL을 기반으로 구축 된 NoSQL 데이터베이스로 변경했습니다.
Uber는 다음과 같은 것들을 고려했습니다.
수평 확장 가능 (Horizontally Scalable) — 서로 다른 지역에 여러 노드를 추가할 수 있으며 모두 하나의 데이터베이스로 작동합니다. (Horizontal Sharding을 사용한 것으로 추측됨)
쓰기 및 읽기 가용성- 4 초마다 운전자의 GPS 위치를 데이터베이스로 전송합니다. 그래서 많은 읽기와 쓰기가 시스템에 발생합니다.
다운 타임 없음 — 시스템을 항상 Available(사용) 해야 하며, 시스템에 추가하거나 제거하는 항목 또는 시스템 유지 보수를 수행하는 동안 시스템이 동작해야 하며, 다운 타임이 없어야합니다.
가장 가까운 데이터 센터 사용 — 시스템에 새 도시를 추가할 때 새 데이터 센터를 추가하거나 새로 추가된 도시의 가장 가까운 데이터 센터에 데이터를 저장하여 원활한 서비스를 제공합니다.
추가적 읽을거리 - 왜 Uber 엔지니어링 팀은 Postgres에서 MySQL로 전환했나
분석 (Analytics)
분석은 우리가 가지고 있는 데이터를 특성을 감지하는 것입니다. Uber는 고객과 CAB(드라이버)의 행동을 이해해야 합니다. 분석은 Uber의 시스템과 운영비를 최적화하고 고객 만족도를 높이는 방법입니다.
Uber는 분석을 위해 다양한 도구와 프레임 워크를 사용합니다. Driver(운전자)의 모든 위치 데이터와 Riders(탑승자)의 데이터는 NoSQL, RDBMS 또는 HDFS에 저장됩니다. 일부 데이터 분석의 경우 실시간 데이터가 필요할 수 있습니다.
KAFKA로부터 (실시간) 데이터를 처리할 수 있습니다(즉 실시간 데이터 처리 능력을 갖추었다). HADOOP 플랫폼은 분석에 사용할 수 있는 많은 분석 관련 도구들로 구성되어 있습니다. HDFS를 사용하여 NoSQL 데이터베이스에서 Dummy 데이터를 얻을 수 있습니다. 그리고 HIVE와 같은 쿼리 도구를 사용하여 HDFS에서 데이터를 가져올 수 있습니다.
데이터베이스의 과거 데이터를 사용하여 KAFKA에서 얻을 수 있는 실시간 데이터와 비교할 수 있으며, 현재 보유하고 있는 지도 데이터를 개선할 수 있는 새로운 지도(방향)를 만들 수 있습니다. 또한 실시간 데이터를 통해 새로운 교통 상황과 운전자의 속도 등을 확인할 수 있습니다. 이는 ETA(여행 예측 시간) 값을 보다 정확하게 식별하는 데 도움이 됩니다.
머신 러닝 및 FRAUD 감지를 위해 Uber는 결제 사기, 인센티브 남용, 계정 도용과 같은 여러 유형의 부정행위를 처리합니다. 부정행위는 플랫폼에서의 사용자 경험뿐만 아니라 우버에도 직접적인 영향을 미칩니다. 악의적인 행위자와 싸우기 위해 Uber는 이 문제를 해결하기 위해 사기 방지 분석가, 데이터 과학자, UX 전문가들로 구성된 전담팀을 두고 있습니다. 이러한 노력의 일환으로 끊임없이 변화하는 부정 행위 환경의 변화를 지속해서 모니터링하고 대응할 수 있는 내부 서비스를 구축하고 있습니다.
이러한 서비스는 합법적인 사용자가 취하지 않았을 잘못된 행위와 액션을 찾습니다. 예를 들어 부정행위 방지 기술을 사용하면 실제 여행과 GPS 스푸핑으로 생성된 여행을 구별하거나, (우리가 만든 부정행위를 모너터링하고 식별하는) 앱이 어떻게 사기꾼들을 드러내는 데 사용되고 있는지 분석할 수 있습니다.
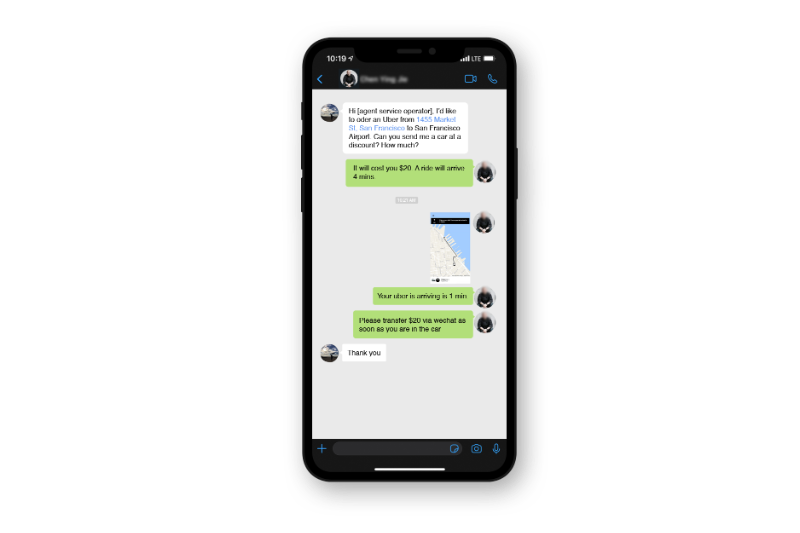
결제 사기
결제 사기는 악의적인 행위자가 도난당한 신용 카드를 사용하여 Uber 여행 비용을 지불할 때 발생합니다. 일반적으로 신용 카드 소유자가 자신의 계좌에서 승인되지 않은 거래를 발견하면 은행 또는 신용 카드 회사에 전화하여 이의를 제기하고 Uber가 청구 금액을 환불합니다. 도난당한 신용 카드로 인한 이익을 극대화하기 위해 사기꾼은 이러한 여행을 하지 않습니다. 대신 에이전트 서비스로 일하면서 (웹 사이트와 채팅 포럼에서) 할인 여행 서비스를 다른 사람들에게 광고합니다.
인센티브 남용
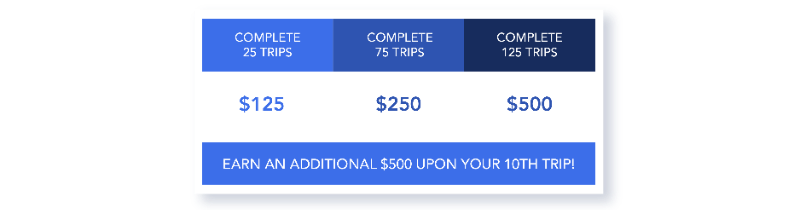
Uber는 새로운 사용자에게 가입 또는 친구 추천에 대한 크레딧을 제공 할 뿐만 아니라 지정된 기간 내에 일정량의 여행을 완료한 운전자를 위해 보너스도 제공합니다. 사기꾼은 이러한 인센티브를 가져가기 위해, 가짜 계정을 만들어 새로운 사용자 및 추천 크레딧을 얻거나 가짜 여행을 시뮬레이션하여 운전자 보너스를 획득하려고 합니다.
손상된 계정 (Compromised accounts)
사기꾼은 또한 피싱 기술을 사용하여 라이더 및 운전자 계정에 액세스합니다. 라이더 계정을 사용하면 사기꾼이 에이전트 서비스를 제공하여 다른 사람에게 탑승권을 판매할 수 있습니다. 운전자 계정에 액세스하면 사기꾼이 돈을 인출할 수 있습니다. 피싱 기술에는 일반적으로 이메일, 문자 메시지 또는 전화 통화가 포함하고 있습니다. 사용자가 암호와 2단계 인증 코드를 넘겨주도록 속입니다.
추가로 읽을거리 - Uber 사례 - 사기를 감지하고 예방하기 위한 고급 기술
어떻게 모든 데이터 센터 장애를 처리해야 합니까?
데이터 센터 오류는 자주 발생하지 않지만 Uber는 원활한 동작을 위해 여전히 백업 데이터 센터를 유지하고 있습니다. 이 데이터 센터에는 모든 구성 요소가 포함되어 있지만 Uber는 기존 데이터를 백업 데이터 센터에 복사하지 않습니다.
그렇다면 Uber는 데이터 센터 장애를 어떻게 해결할까요??
데이터 센터 장애 문제를 해결하기 위해 실제로 운전자 폰을 승하차 데이터의 소스로 사용합니다. 운전자의 전화 앱이 디스패치 시스템과 통신하거나 API 호출이 발생하면 디스패치 시스템은 (최신 정보 / 데이터를 추적하기 위해) 암호화된 상태 메시지(State Message)를 운전자의 전화 앱으로 보냅니다.
이 상태 메시지(State Message)는 항상 운전자의 전화 앱에서 받을 수 있습니다.
데이터 센터 고장 시 백업 데이터 센터(백업 DISCO)는 이동 정보(trip)에 대해 아는 바가 없어 운전자 전화 앱에서 상태 다이제스트를 요청하고 운전자 전화 앱에서 수신한 상태 메시지(State Message) 정보로 자체 업데이트합니다.
이상으로 Uber 아키텍처 및 시스템 디자인의 모든 컴포넌트를 배웠습니다.
*****
이 글은 Kasun Dissanayake 님의 Uber Architecture and System Design를 번역한 글입니다. 모든 권한은 원 저작자에게 있으며 지식 공유 차원에서 번역을 했습니다.
최신 콘텐츠