template첫 번째와 두 번째 파라미터는 정렬하려는 구간의 시작과 마지막을 가리키는 반복자입니다. 비교 조건자를 필요로 하지 않고 기본형을 저장한 컨테이너를 오름차순으로 정렬합니다.void sort( RandomAccessIterator _First, RandomAccessIterator _Last );
template첫 번째와 두 번째 파라미터는 정렬하려는 구간의 시작과 마지막을 가리키는 반복자입니다. 세 번째 파라미터는 정렬 방법을 기술한 비교 조건자입니다.void sort( RandomAccessIterator _First, RandomAccessIterator _Last, BinaryPredicate _Comp );
vector< 리스트 1. less와 greater 비교 조건자를 사용한 sort >vec1; ….. // 오름차순 정렬 sort( vec1.begin(), vec1.end() ); // 내림차순 정렬 Sort( vec1.begin(), vec1.end(), greater () );
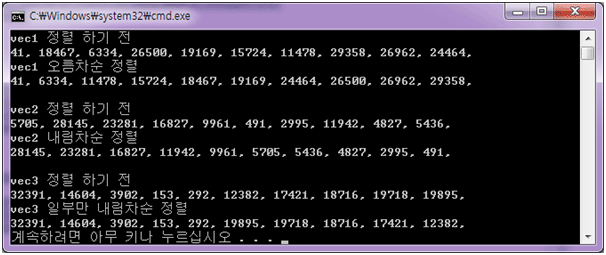
#include< 결과 >#include #include #include using namespace std; int main() { vector vec1(10); vector vec2(10); vector vec3(10); vector ::iterator Iter1; generate( vec1.begin(), vec1.end(), rand ); generate( vec2.begin(), vec2.end(), rand ); generate( vec3.begin(), vec3.end(), rand ); // 오름차순 정렬 cout << "vec1 정렬 하기 전" << endl; for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; sort( vec1.begin(), vec1.end() ); cout << "vec1 오름차순 정렬" << endl; for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; cout << endl; // 내림차순 정렬 cout << "vec2 정렬 하기 전" << endl; for( Iter1 = vec2.begin(); Iter1 != vec2.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; sort( vec2.begin(), vec2.end(), greater () ); cout << "vec2 내림차순 정렬" << endl; for( Iter1 = vec2.begin(); Iter1 != vec2.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; cout << endl; // 일부만 내림차순 정렬 cout << "vec3 정렬 하기 전" << endl; for( Iter1 = vec3.begin(); Iter1 != vec3.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; sort( vec3.begin() + 5, vec3.end(), greater () ); cout << "vec3 일부만 내림차순 정렬" << endl; for( Iter1 = vec3.begin(); Iter1 != vec3.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; return 0; }
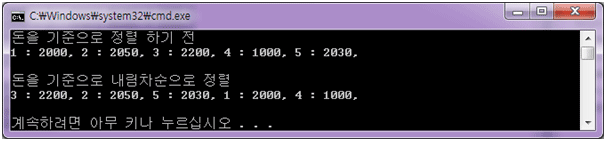
#include< 결과 >#include #include #include using namespace std; struct USER { int UID; int Level; int Money; }; struct USER_MONEY_COMP { bool operator()(onst USER& user1, const USER& user2) { return user1.Money > user2.Money; } }; int main() { USER User1; User1.UID = 1; User1.Money = 2000; USER User2; User2.UID = 2; User2.Money = 2050; USER User3; User3.UID = 3; User3.Money = 2200; USER User4; User4.UID = 4; User4.Money = 1000; USER User5; User5.UID = 5; User5.Money = 2030; vector Users; Users.push_back( User1 ); Users.push_back( User2 ); Users.push_back( User3 ); Users.push_back( User4 ); Users.push_back( User5 ); vector ::iterator Iter1; cout << "돈을 기준으로 정렬 하기 전" << endl; for( Iter1 = Users.begin(); Iter1 != Users.end(); ++Iter1 ) { cout << Iter1->UID << " : " << Iter1->Money << ", "; } cout << endl << endl; sort( Users.begin(), Users.end(), USER_MONEY_COMP() ); cout << "돈을 기준으로 내림차순으로 정렬" << endl; for( Iter1 = Users.begin(); Iter1 != Users.end(); ++Iter1 ) { cout << Iter1->UID << " : " << Iter1->Money << ", "; } cout << endl << endl; return 0; }
templatebinary_search 사용 방법bool binary_search( ForwardIterator _First, ForwardIterator _Last, const Type& _Val ); template bool binary_search( ForwardIterator _First, ForwardIterator _Last, const Type& _Val, BinaryPredicate _Comp );
vectorbinary_search는 정렬한 이후에 사용해야 한다고 앞서 이야기 했습니다. 만약 정렬하지 않고 사용하면 어떻게 될까요?vec1; ….. sort( vec1.beign(), vec1.end() ); …... bool bFind = binary_search( vec1.begin(), vec1.end(), 10 );
int main()
{
vector vec1;
vec1.push_back(10); vec1.push_back(20); vec1.push_back(15);
vec1.push_back(7); vec1.push_back(100); vec1.push_back(40);
vec1.push_back(11); vec1.push_back(60); vec1.push_back(140);
bool bFind = binary_search( vec1.begin(), vec1.begin() + 5, 15 );
if( false == bFind ) {
cout << "15를 찾지 못했습니다." << endl;
} else {
cout << "15를 찾았습니다." << endl;
}
return 0;
}
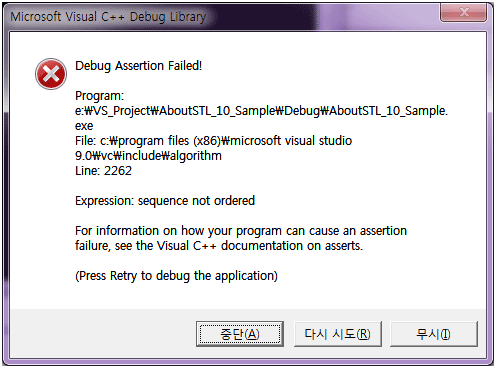
디버그 모드로 빌드 후 실행 하면 아래와 같은 에러 창이 나옵니다.
#include< 결과 >#include #include #include using namespace std; int main() { vector vec1; vec1.push_back(10); vec1.push_back(20); vec1.push_back(15); vec1.push_back(7); vec1.push_back(100); vec1.push_back(40); vec1.push_back(11); vec1.push_back(60); vec1.push_back(140); sort( vec1.begin(), vec1.end() ); bool bFind = binary_search( vec1.begin(), vec1.begin() + 5, 15 ); if( false == bFind ) { cout << "15를 찾지 못했습니다." << endl; } else { cout << "15를 찾았습니다." << endl; } return 0; }

……. sort( Users.begin(), Users.end(), USER_MONY_COMP() ); bool bFind = binary_search( Users.begin(), Users.begin() + 3, User5, USER_MONY_COMP() ); …….10.1.3 merge
templatemerge 사용 방법OutputIterator merge( InputIterator1 _First1, InputIterator1 _Last1, InputIterator2 _First2, InputIterator2 _Last2, OutputIterator _Result ); template OutputIterator merge( InputIterator1 _First1, InputIterator1 _Last1, InputIterator2 _First2, InputIterator2 _Last2, OutputIterator _Result, BinaryPredicate _Comp );
vector아래의 <리스트 5>는 vec1과 vec2를 합쳐서 vec3에 넣는 것으로 vec1과 vec2는 이미 정렬되어 있고 vec3는 이 vec1과 vec2의 크기만큼의 공간을 미리 확보해 놓고 있습니다.vec1, vec2, vec3; ….. merge( vec1.begin(), vec1.end(), vec2.begin(), vec2.end(), vec3.begin() );
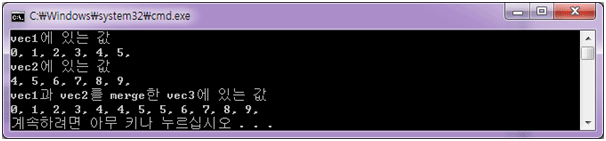
#include< 결과 >#include #include #include using namespace std; int main() { vector ::iterator Iter1; vector vec1,vec2,vec3(12); for( int i = 0; i < 6; ++i ) vec1.push_back( i ); for( int i = 4; i < 10; ++i ) vec2.push_back( i ); cout << "vec1에 있는 값" << endl; for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; cout << "vec2에 있는 값" << endl; for( Iter1 = vec2.begin(); Iter1 != vec2.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; merge( vec1.begin(), vec1.end(), vec2.begin(), vec2.end(), vec3.begin() ); cout << "vec1과 vec2를 merge한 vec3에 있는 값" << endl; for( Iter1 = vec3.begin(); Iter1 != vec3.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; return 0; }
template첫 번째와 두 번째 파라미터는 구간이며, 세 번째 파라미터는 구간에 있는 값에 더할 값입니다.Type accumulate( InputIterator _First, InputIterator _Last, Type _Val );
template네 번째 파라미터는 조건자로 조건자를 사용하여 기본 자료 형 이외의 데이터를 더할 수 있고, 더하기 연산이 아닌 다른 연산을 할 수도 있습니다.Type accumulate( InputIterator _First, InputIterator _Last, Type _Val, BinaryOperation _Binary_op );
vector아래의 <리스트 6>은 int를 저장하는 vector를 대상으로 accmurate를 사용하는 가장 일반적인 예입니다.vec1; ….. // vec1에 있는 값들만 더 한다. int Result = accmulate( vec1.begin(), vec1.end(), 0, );
#include< 결과 >#include #include using namespace std; int main() { vector ::iterator Iter1; vector vec1; for( int i = 1; i < 5; ++i ) vec1.push_back( i ); // vec1에 있는 값 for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) { cout << *Iter1 << ", "; } cout << endl; // vec1에 있는 값들을 더한다. int Result1 = accumulate( vec1.begin(), vec1.end(), 0 ); // vec1에 있는 값들을 더한 후 10을 더 한다. int Result2 = accumulate( vec1.begin(), vec1.end(), 10 ); cout << Result1 << ", " << Result2 << endl; }

#include< 결과 >#include #include using namespace std; struct USER { int UID; int Level; int Money; }; struct USER_MONY_ADD { USER operator()(const USER& user1, const USER& user2) { USER User; User.Money = user1.Money + user2.Money; return User; } }; int main() { USER User1; User1.UID = 1; User1.Money = 2000; USER User2; User2.UID = 2; User2.Money = 2050; USER User3; User3.UID = 3; User3.Money = 2200; USER User4; User4.UID = 4; User4.Money = 1000; USER User5; User5.UID = 5; User5.Money = 2030; vector Users; Users.push_back( User1 ); Users.push_back( User2 ); Users.push_back( User3 ); Users.push_back( User4 ); Users.push_back( User5 ); vector ::iterator Iter1; for( Iter1 = Users.begin(); Iter1 != Users.end(); ++Iter1 ) { cout << Iter1->UID << " : " << Iter1->Money << ", "; } cout << endl << endl; // Users에 있는 Money 값만 더하기 위해 Money가 0인 InitUser를 세 번째 파라미터에 // 조건자를 네 번째 파라미터로 넘겼습니다. USER InitUser; InitUser.Money = 0; USER Result = accumulate( Users.begin(), Users.end(), InitUser, USER_MONY_ADD() ); cout << Result.Money << endl; }

template조건자를 사용하는 버전으로 조건자를 사용하면 유저 정의형을 사용할 수 있는 내적 연산 방법을 바꿀 수 있습니다.Type inner_product( InputIterator1 _First1, InputIterator1 _Last1, InputIterator2 _First2, Type _Val );
template아래의 <리스트 8>은 조건자를 사용하지 않는 inner_product를 사용하는 것으로 vec1과 vec2의 내적을 계산합니다.Type inner_product( InputIterator1 _First1, InputIterator1 _Last1, InputIterator2 _First2, Type _Val, BinaryOperation1 _Binary_op1, BinaryOperation2 _Binary_op2 );
#include< 결과 >#include #include using namespace std; int main() { vector vec1; for( int i = 1; i < 4; ++i ) vec1.push_back(i); vector vec2; for( int i = 1; i < 4; ++i ) vec2.push_back(i); int Result = inner_product( vec1.begin(), vec1.end(), vec2.begin(), 0 ); cout << Result << endl; return 0; }

이전 글 : About STL : C++ STL 프로그래밍(9)-알고리즘1
다음 글 : 웹 스퀘어드 : 5년 간의 Web 2.0의 행적

최신 콘텐츠