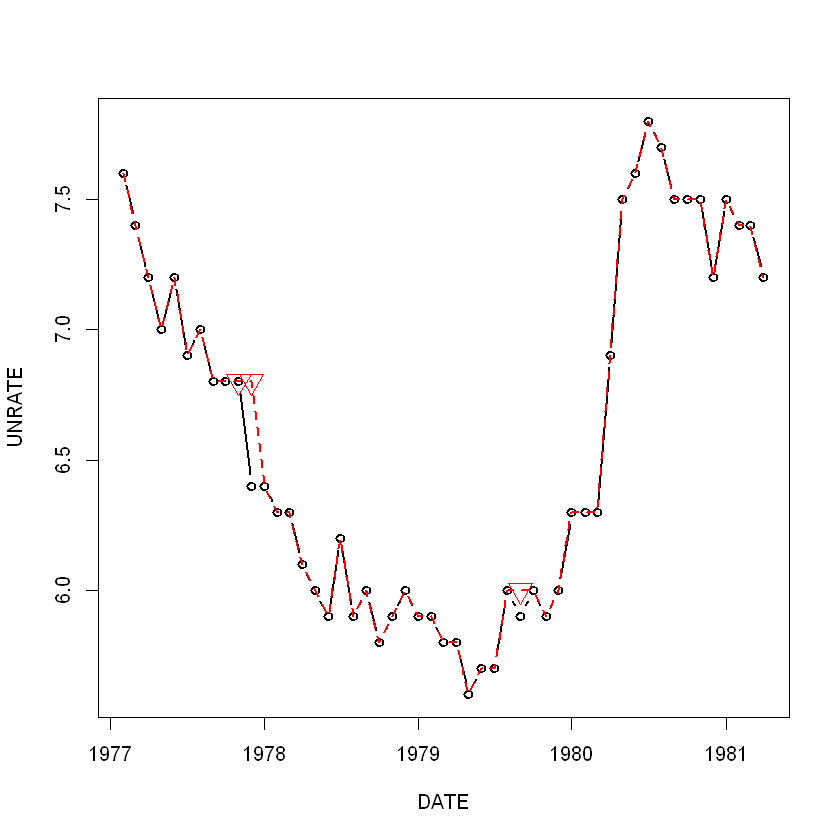
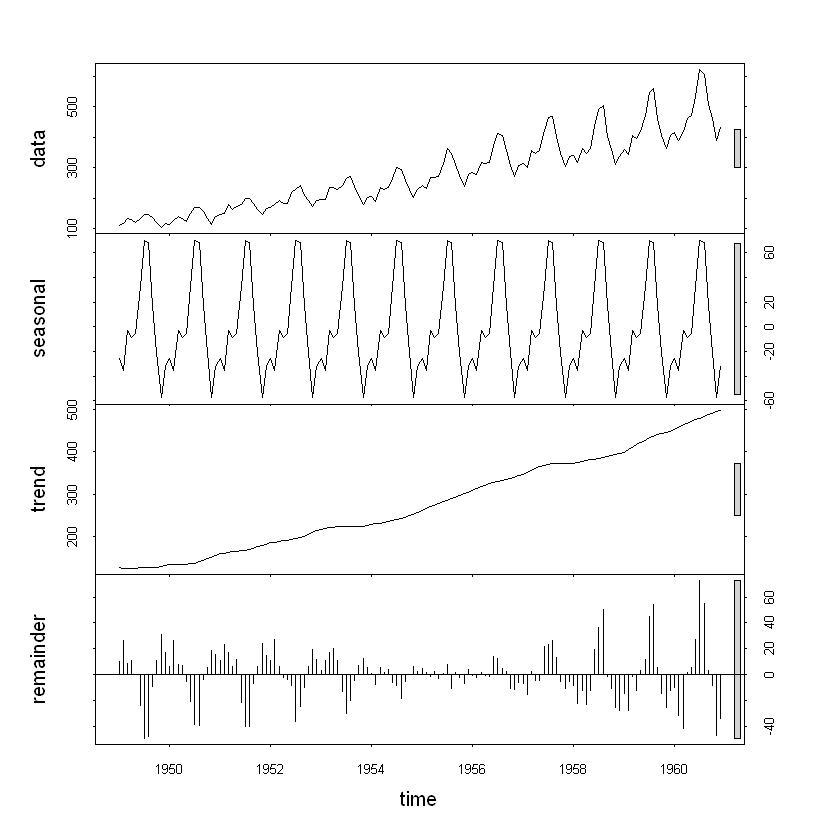
실전 시계열 분석을 받기 전에 이 책이 나에게 주식 부자가 되게 해줄 마법의 책이 되기 않을까 살짝 기대해보았어요.
훗, 역시 기대가 빗나갔습니다. 대신 이 책은 앞으로 다가올 딥러닝계의 포인트를 찍어주었어요.
바로 시계열이죠. 쉽게 생각해서 시간 개념을 도입한다고 보시면 됩니다.
우리가 분석하는 데이터중 많은 것은 시간 개념이 들어가 있습니다.
저는 MS Power BI 시각화 툴을 사용하면서(파이썬으로 분석할 때 보다), 그래프를 많이 그리게 되었습니다.
그때 놀란 것이 시간 데이터 삽입과 공간 데이터 삽입으로 데이터를 훨씬 더 풍부하게 살펴볼 수 있게 되었다는 점입니다.
이 책은 저처럼 대충 시계열을 알고 있는 사람들이 읽어보면 좋을 내용들이 가득합니다.
왜 그런지 좀 더 살펴볼까요?

일단 이 책에서 필수 배경지식으로 R과 파이썬에 어느 정도 익숙해야 한다고 합니다.
아닙니다. 초중급 실력은 되어야 합니다. 그냥 파이썬 좀 아는 정도로는 이 책의 예제 소스 코드를 이해할 수 없습니다.
소스 코드에 약하더라도, 시계열에 대한 여러 생각거리를 던져주므로, 비개발자라고 하더라도(조금 어렵더라도) 미리 읽어볼 가치는 있다고 생각합니다.

집필의도에서 보면 시계열 분석에 대한 자료나 책이 없다고 합니다. 맞습니다. 그래서 이 책이 다소 어렵습니다.
앞으로 시계열 분석에 대한 요구가 많아지면, 좀 더 쉬운 내용들의 책들이 나오겠죠.
그리도 시계열에 대한 전체 구성에서 다양한 시각을 보여주고, 주요한 이야기거리를 던져주므로, 언젠가는 읽어야 할 것 같습니다.

목차가 앞쪽에는 통계기반 분석을, 뒷쪽에는 딥러닝쪽입니다.
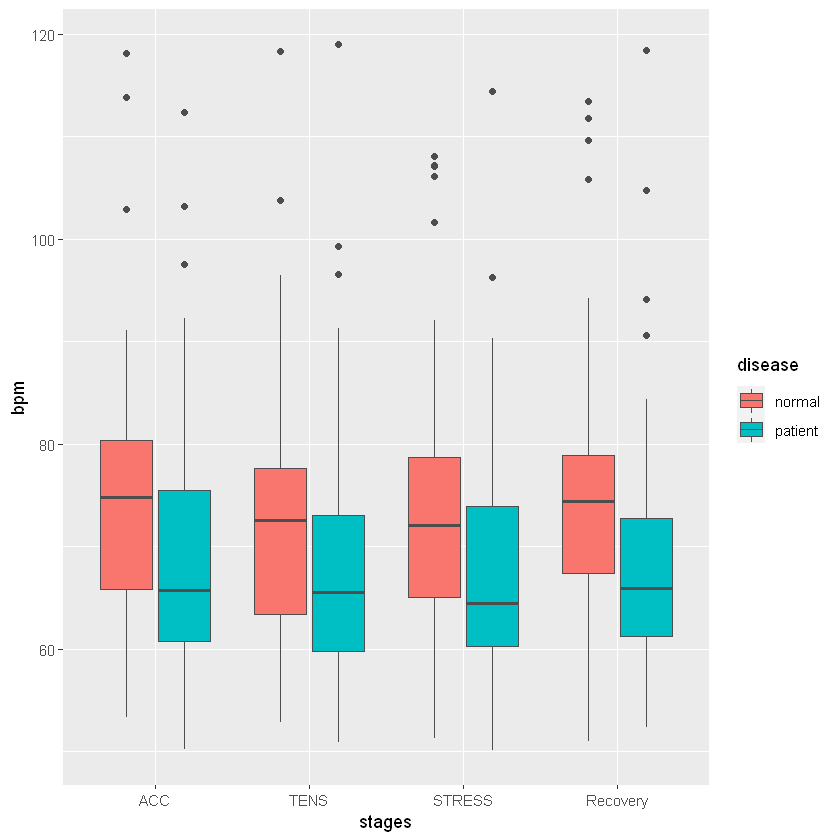
전 13장부터 나오는 헬스케어 애플리케이션과 같은 실전 사례가 더 마음에 들었습니다.
머신러닝, 통계 모델을 잘 몰라서, 초반에는 읽기 힘들어서 그런지도 모르겠어요.

이 책에는 실전 예제로 소스 코드를 수록하였습니다.
설명은 R 과 Python 으로 각 사례별로 잘 맞는 언어를 사용해서 설명합니다.
문제는 우리가 R과 Python 둘 다 사용하지 않는다는 점이죠. 파이썬을 하는 입장에서 R 소스 코드를 보면 답답해지는 것이죠.
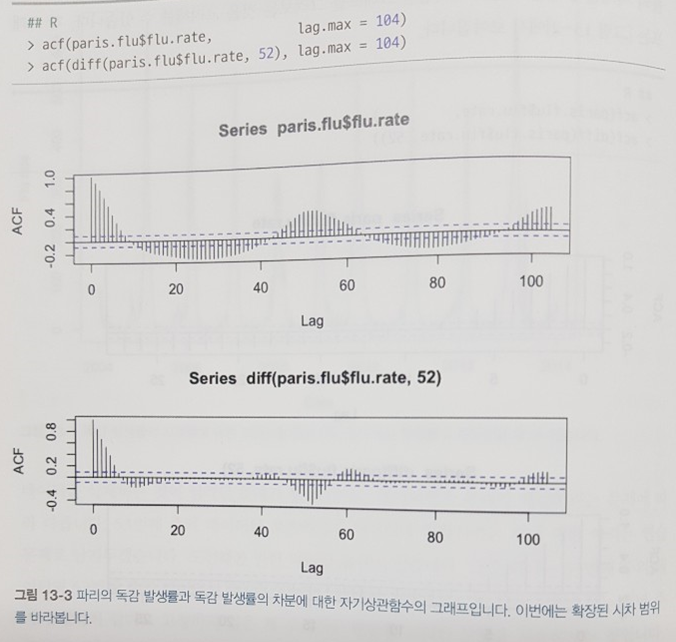
문제는 파이썬을 좀 하거나, 배운 입장에서는 위 이미지의 소스 코드는 이해하시겠죠.
그런데, 분석 쪽을 한번도 하지 않으신 분 같으면, 일반 파이썬 기초만 공부하셨다면 어려울 수 있습니다.
소스 코드 한 줄 한 줄에 대한 설명은 하지 않습니다.
필요하면 소스 코드와 그래프를 많이 제공하기 때문에, 소스 코드를 못 읽더라도, 전체적인 개념 익히기나 공부하기에 많은 도움이 됩니다.
소스 코드는 천천히 공부하시면서, 익히시면 되니까요.

책이 거의 560 쪽 입니다.
시계열에 대해서 상당히 많이 서술하였습니다. 일반 데이터 분석할 때의 순서대로 책 내용이 구성되어 있습니다.
각 내용에서 시계열 입장에서 다시 보충, 추가 설명했다고 보시면 됩니다.
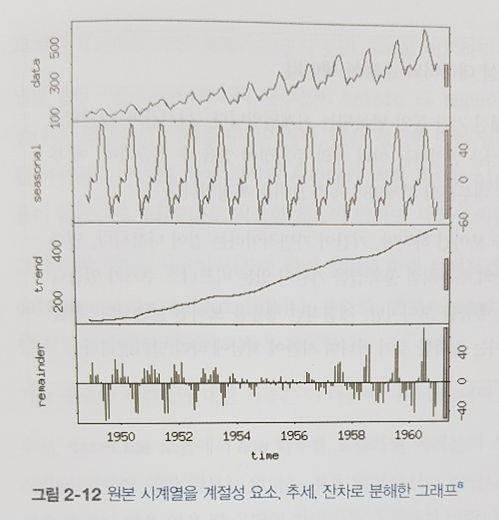
시간을 어떻게 잡고, 어떻게 수집하고, 어떻게 저장할까? 앞 쪽에서 많이 할애하는데, 이 책을 읽고 정말 중요하다고 다시금 되새기게 되었습니다.
시계열 개념 자체가 알아야 할 것들이 많은데, 이런 것들을 책 곳곳에 있습니다.
데이터 분할도 일반적으로 하는 것과 왜 달리해야 하는지도 중요하고요.
딥러닝쪽을 좀 더 많이 봐온 저로서는 통계 모델과 수식이 좀 어려웠습니다.

책 리뷰를 하기 위해, 다시 처음부터 쭉~ 넘겨보니, 지금 적고 있는 것보다 훨씬 더 많은 이야기들을 적고 싶었는데, 빠트린 것들이 너무 많네요.
통계, 딥러닝으로 시계열로 데이터 분석하고 싶으시다면, 처음부터 빼놓치 마시고, 시계열 관점에서 하나하나 의심을 가지고 기존에 아시던 것에 물음을 해보세요.
저는 많은 배움을 안겨준 책이라, 다음에 시계열 분석을 해야한다면 옆에 놓고 다시 보려고 합니다.
책에 나온 많은 용어와 개념이 이해가 안되는 부분들이 많아서, 또다른 영역의 공부도 많이 해야 할 것 같습니다.
그러나, 앞으로 모든 분석에 시간 개념이 차츰 들어갈 것 같고, 오늘의 이 고통이 내일의 초석이 되었으면 하는 바램입니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."