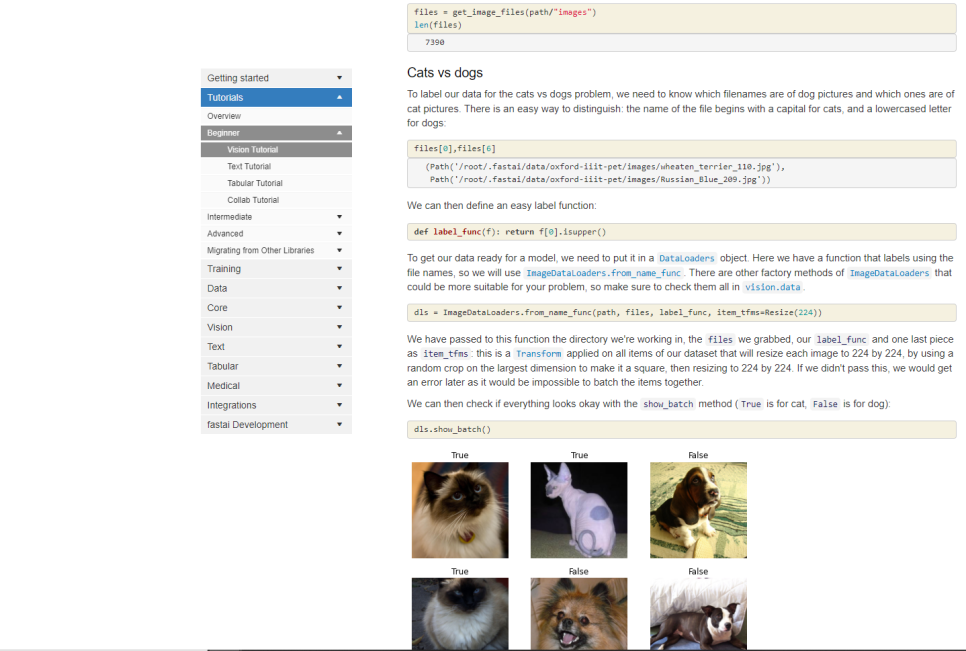
널리 개발자를 이롭게 할 최첨단 딥러닝 기술 fast.ai의 모든 것
이 책의 원서는 미국 아마존 컴퓨터 신경망 분야에서 최상위권 자리를 지키고 있습니다. 제일 뜨거운 주제인 fastai 라이브러리를 사용해 딥러닝을 설명하기 때문이죠. 개발과 데이터에 관심을 가지기 시작한 분들과 대화하다 보면 전산 전공자가 아니고, 개발자 출신이 아니기 때문에 코드가 나오는 일을 잘하지 못할 것이라 걱정하는 분들이 계십니다. 당연히 그럴 수 있습니다. 기술을 처음 접할 때는 풀어야 할 문제, 풀고 싶은 문제를 위해 스스로 무엇을 알아야 하는지 몰라서 좌절하기 쉽습니다. 이러한 분들은 이 책을 통해 딥러닝 엔지니어링을 향한 호기심을 충분히 충족할 수 있을 것입니다.
추천사
완전히 밑바닥에서부터 최첨단 연구까지 이끌어줄 가이드를 찾는 이에게 적합한 책입니다. 학위 소지자뿐만 아니라 여러분도 실제 문제 해결에 딥러닝을 사용하는 재미를 느끼게 될 것입니다.
_할 바리안, 구글 수석 경제학자이자 캘리포니아 대학교 버클리 회계학과 교수
인공지능이 딥러닝 시대로 접어들면서, 최대한 딥러닝의 작동 원리를 많이 배우는 것이 당연해졌습니다. 이 책은 매우 복잡하다고 여겨진 개념을 아직 배우지 않은 사람도 쉽게 학습할 수 있는 훌륭한 방법을 제공합니다.
_에릭 토폴, 스크립스 연구소 교수이자 『딥메디슨』 저자
제러미와 실뱅은 노트북 환경에서 대화형 방식으로 코드를 한 줄 한 줄 실행하며 딥러닝의 성능 최고점과 손실 계곡에 대한 여행을 안내합니다. 수년간 머신러닝 분야의 개발과 교육에서 얻은 통찰과 실용적인 직관으로 뒤덮인 이 책은 깊이 있는 기술적 개념을 가벼운 대화형 방식으로 풀어내는 균형 잡힌 접근법으로 쓰였습니다. 온라인 교육 수상 경력에 빛나는 fast.ai의 철학을 충실히 반영한 이 책은 실용적인 최신 도구와 이를 사용해볼 수 있는 실제 사례를 함께 제공합니다. 초보자, 전문가를 가리지 않고 딥러닝 여정을 빠르게 여행하고, 폭넓고 깊이 있는 지식을 얻게 될 것입니다.
_서배스천 루더, 딥마인드 연구 과학자
이 책은 인공지능과 그 외 분야를 성공적으로 연결하는 제러미 하워드와 실뱅 거거의 훌륭한 저술서입니다. 매우 실질적인 통찰을 제공할 뿐만 아니라, 딥러닝에 관련된 모든 사람에게 기본 지침서로도 손색이 없습니다.
_앤서니 창, 오렌지 카운티 아동병원 정보 혁신 기관장
어떻게 늪에 빠지지 않고 딥러닝을 습득할 수 있을까요? 예제와 코드를 통해 개념, 기술, 기법을 빠르게 배울 방법은 무엇일까요? 실습을 통한 딥러닝 입문서 표준의 한 획을 긋는 이 책을 놓치지 마세요.
_오렌 에치오니, 앨런 인공지능 기관 CEO 및 워싱턴 주립대학교 교수
이 책은 수년간 수천 명의 학생들을 성공적으로 길러낸 경험을 토대로 신중하면서도 매우 효과적으로 작성된 산물입니다. 저도 그 학생 중 한 명이며 fast.ai는 저의 삶을 멋지게 바꿨습니다. 여러분도 마찬가지의 경험을 할 수 있다고 확신합니다.
_제이슨 앤틱, DeOldify 제작자
이 책은 매우 훌륭한 자료입니다. 시간을 허투루 낭비할 내용이 하나도 없습니다. 처음 몇 장에서는 딥러닝을 효과적으로 사용하는 방법을 가르치며, 그다음 머신러닝 모델과 프레임워크의 내부 작동 방법을 철저히 그러나 쉽게 접근할 수 있는 방식으로 설명합니다. 제가 머신러닝을 배웠을 때도 이런 명서가 있었다면 정말 좋았을 겁니다.
_에마뉘엘 아메장, 『Building Machine Learning Powered Applications』 저자
이 책의 1장 1절의 ‘모두를 위한 딥러닝’이라는 말은 다른 책에서도 흔히 볼 수 있는 주장이지만, 이 책만큼 이 주장을 잘 전달하는 경우는 없었습니다. 저자는 머신러닝에 대한 광범위한 지식을 가지고 있을 뿐만 아니라, 프로그래밍 경험은 있지만 머신러닝을 모르는 독자에게 매우 적합한 방식의 설명을 제공하고 있습니다. 이 책은 구체적인 예시를 먼저 제시하고, 그 예시의 맥락에 이론을 첨가하는 방식으로 설명합니다. 또한 영상 처리, 자연어 처리, 테이블 데이터 처리에 적용되는 딥러닝의 응용 사례뿐만 아니라, 다른 책에서는 찾아보기 힘든 데이터 윤리와 같은 주제도 함께 다루기 때문에 매우 인상적입니다. 이 책은 딥러닝에 능숙해지고 싶은 프로그래머에게 최고의 자료입니다.
_피터 노빅, 구글 연구소장
이 책은 코딩을 조금이라도 해본 사람이 딥러닝을 접하기에 가장 이상적인 자료입니다. 책과 더불어 fast.ai 교육 과정을 직접 탐색하고, 재사용 가능한 코드를 제공하여 딥러닝을 실용적으로 쉽게 설명해 줍니다. 더는 추상적인 개념에 대한 정리와 증명을 어렵게 익히지 않아도 됩니다. 1장에서는 첫 번째 딥러닝 모델을 구축하고 이 책이 끝날 무렵에는 딥러닝 논문을 읽고 이해하는 방법을 깨우치게 될 것입니다.
_커티스 랑글로츠, 스탠퍼드 대학교 인공지능 의학 및 이미징 센터장
이 책은 딥러닝이라는 블랙박스의 가장 어두운 부분을 쉽게 이해할 수 있게 해줍니다. 파이썬으로 작성된 완전한 노트북으로 빠르게 실험할 수도 있습니다. 또한 인공지능에 내재된 윤리적 문제를 깊이 있게 다루어 디스토피아가 되는 것을 방지하는 방법을 보여줍니다.
_기욤 샬로, 모질라 펠로우
OpenAI 연구자로 전향한 전 피아니스트로서, 딥러닝에 뛰어드는 방법을 물어보는 사람들에게 항상 fastai를 추천합니다. 이 책은 복잡한 주제를 친근하게 안내할 뿐만 아니라, 숙련된 실무자에게도 유용한 최신 기법을 다루는 등 주옥같은 내용으로 가득 차 있습니다. 완전히 다른 두 집단 모두를 위한 어려운 작업을 해낸 책입니다.
_크리스틴 페인, 뮤즈넷과 쥬크박스 제작자이자 OpenAI 연구자
누구나 딥러닝 프로젝트를 빠르게 시작하는 데 도움이 되는 실습 위주의 접근성이 뛰어난 책입니다. 실용적인 딥러닝에 대해 매우 명확하고 따르기 쉬운 정직한 가이드를 제공합니다. 초보자부터 경영진, 관리자까지 모든 이에게 유용한 자료입니다. 수년 전에 이 책이 있었다면 너무 좋았을 것 같습니다!
_캐럴 라일리, Drive.ai 설립 이사이자 의장
제러미와 실뱅의 딥러닝에 대한 전문성, 머신러닝에 대한 실용적 접근법, 그리고 이들이 이바지해온 오픈소스는 파이토치 커뮤니티의 핵심 중 하나입니다. 머신러닝의 접근성을 더욱 쉽게 만들기 위해 fast.ai 커뮤니티가 해온 작업의 일환인 이 책은 AI 전체 분야에 큰 도움이 될 것입니다.
_제롬 페센티, 페이스북 AI 부사장
딥러닝은 최근 인공지능의 놀라운 발전을 책임지고 있는 현재 가장 중요한 기술 중 하나입니다. 이전에는 박사 학위 소지자만을 위한 분야였지만, 이제는 아닙니다! 매우 인기 있는 fast.ai 교육 과정을 기반으로 작성된 이 책은 프로그래밍 경험이 있는 모든 사람이 딥러닝에 접근할 기회를 제공합니다. 훌륭한 실습 예제, 대화형으로 실행해볼 수 있는 사이트와 함께 딥러닝이 탑재된 시스템의 ‘전체’를 가르칩니다. 또한 박사 학위 소지자에게도 유익한 내용이 많이 담겨 있습니다.
_그레고리 피아테스키-샤피로, KDnuggets 사장
최고의 딥러닝 전문가인 제러미와 실뱅이 저술한 이 책은 제가 지난 수년간 꾸준히 추천해온 fast.ai 교육 과정의 연장선으로, 수개월 만에 초심자에서 자격을 갖춘 실무자가 되는 길을 안내합니다.
_루이스 모니어, 전 에어비앤비 인공지능 연구소장이자 알타비스타 설립자
이 책을 강력하게 추천합니다! 고급 프레임워크로 구체적인 실제 인공지능 및 자동화 작업을 빠르게 다뤄볼 수 있습니다. 또한 모델을 안전하게 상품화하는 방법, 절실히 필요한 데이터 윤리와 같이 일반적으로 간과되는 주제도 함께 다룹니다.
_존 마운트와 니나 주멜, 『R로 배우는 실무 데이터 과학』 저자
이 책은 파이토치 기반으로 구축된 강력한 머신러닝 프레임워크이자 탄탄한 커뮤니티인 fast.ai와 함께할 때 책 이상의 가치를 지니게 됩니다. 일류 산업 연구실에서 경쟁력을 갖출 수 있는 최신 기법들을 타협 없이 약간의 계산만으로 즉시 사용 가능한 수준으로 제공합니다. 개인적으로 이 책과 함께 fast.ai 교육 과정이 지닌 교육과 학습에 대한 철학은 여러 차원에서 개인적 성장을 가속화할 수 있는 도구를 제공합니다. fast.ai 교육 과정과 이 책을 통해 소프트웨어 공학, 테스트, 반복적 개발 방법론, 윤리적 프레임워크에 대한 귀중한 경험을 배울 수 있습니다. 이 책을 통해 제러미의 정신을 엿볼 수 있습니다. 마지막으로 제러미와 실뱅의 교육 방식은 항상 이해심과 공감력에 기초하고 있고, 이는 오늘날 가장 접근성이 좋은 딥러닝 책을 탄생시켰습니다.
_하멜 후사인, CodeSearchNet 프로덕트 리드 및 깃허브 머신러닝 엔지니어
이 책은 ‘프로그래머를 위한’ 것이며, 박사 학위는 전혀 필요하지 않습니다. 저는 박사 학위 소지자이고, 프로그래머가 아닌데 왜 이 책을 검토했을까요? 바로 이 책이 얼마나 굉장한지를 알려드리기 위해서 입니다! 여러분은 1장의 몇 페이지 내로 4줄의 코드와 1분 미만의 계산량으로 고양이와 개를 분류하는 최신 신경망을 구축하는 방법을 배우게 됩니다. 그다음 모델을 상품화하는 2장에서는 서버, HTML, 자바스크립트 없이 웹 애플리케이션을 즉시 배포하는 방법을 배웁니다. 이 책을 양파에 비유하고 싶습니다. 가능한 최고의 설정으로 작동하는 완전한 패키지로 시작해서, 일부 변경이 필요하다면 하나의 껍질을 벗겨내면 되기 때문이죠. 좀 더 많은 변경이 필요하다고요? 그러면 계속해서 더 많은 껍질을 벗겨내면 됩니다. 그렇게 순수 파이토치를 사용하는 수준까지 껍질을 벗겨나갈 수 있습니다. 이 많은 분량의 여정 동안 세 명의 독립적인 목소리는 각 주제에 대해 지침과는 개별적인 관점을 접하는 기회도 제공합니다.
_알프레도 칸지아니, 뉴욕 대학교 컴퓨터 과학 교수
이 책은 접근성이 좋으며, 대화형 방식으로 작성된 책으로 딥러닝 개념을 전체적인 관점에서 가르칩니다. 이 책은 실제 예제를 즉시 다뤄볼 기회와 함께, 필요한 경우에서만 독자에게 참고용 개념을 제공하는 데 집중합니다. 실무자의 경우 전반부 실습을 통해 딥러닝 세계를 접할 수도 있지만, 후반부로 직행하여 더 심도 있는 개념을 자연스럽게 접하는 것도 가능합니다.
_조시 패터슨, 패터슨 컨설팅
여러분의 모델이 원하는 대로 작동하지 않을 때 이 책을 읽어보세요! 제러미의 실제 경험과 실뱅의 이론적 지식의 훌륭한 결합을 제공할 뿐만 아니라, 딥러닝의 기술에 더욱 쉽게 접근할 수 있도록 해줍니다.
_론 코하비, 에어비앤비 기술 펠로우이자 부사장
제러미, 실뱅, 레이철은 인공지능 분야의 커뮤니티와 접근성이 뛰어난 도구를 만드는 데 있어 통달한 분들입니다. 이 책은 전 세계적으로 미래의 인공지능 연구자가 될 수천 명이 쉽게 관련 분야를 습득하는 데 도움이 되는 fast.ai 팀의 또 다른 역작입니다. 축하드립니다!
조 스피삭, 페이스북 파이토치 프로덕트 관리자