그냥 지나갈 뻔 했는데, 사이트의 리뷰 시스템에서 별점을 굳이 주라고하니까 다시 생각된다.
인공지능, 머신러닝 관련해서 몇 권을 훑어봤는데, 그 중에서 흡수력, 구성면에서 제일 낫다. 역사를 다루고, 자세하게 들어가는 건 몇 개 더 있는데, 2천 몇 페이지 그거 다 읽을 시간 없다. 그리고, 그거 다 읽고서 내 것으로 만들어서 논문 쓸 일 없다. 이게 제일최적이다.
일단, 개인적으로 문서 관련 부분을 제대로 다뤄주니 좋았고, 실무에서 쓰던 사람들이 집필한 책이라는 느낌이 들어서 좋았다.
실무자들이 집필했기 때문에 내가 바로 써먹는 건 한계가 있겠지만, 그들이어떻게 썼다는 흐름만 이해해도 내게는 이득이다.
특히 이론 다 설명해놓고서 Ch. 8의 문제점 해결하기 를 제시하는것은 현업에서는 주로 디버깅이나 “문제 해결” 에 노력이쓰인다는 면에서 가려울 때 제대로 긁어주는 느낌이다.
항상 책에 나온 수식과 선이 연결된 복잡도가 있을 때에 특히 소프트웨어로만 된 경우에는 실제 복잡도는 그것의 100배에 해당하는 것이라고 머리 속에서 확장을 해서 봐야 한다.
3 * 3 정도로 표시가 되어 있다고 하면 기본으로 30 * 30 정도의 복잡도를 고려해야 할 것이다. 이것을 잊어버리고하다보면 처음에는 손쉽게 여기면서 하찮게 여길수도, 나중에는 의외의 복잡도에 놀라서 스스로 실망하게될 수도 있다. 항상 어느 정도의 각오는 필요하다.
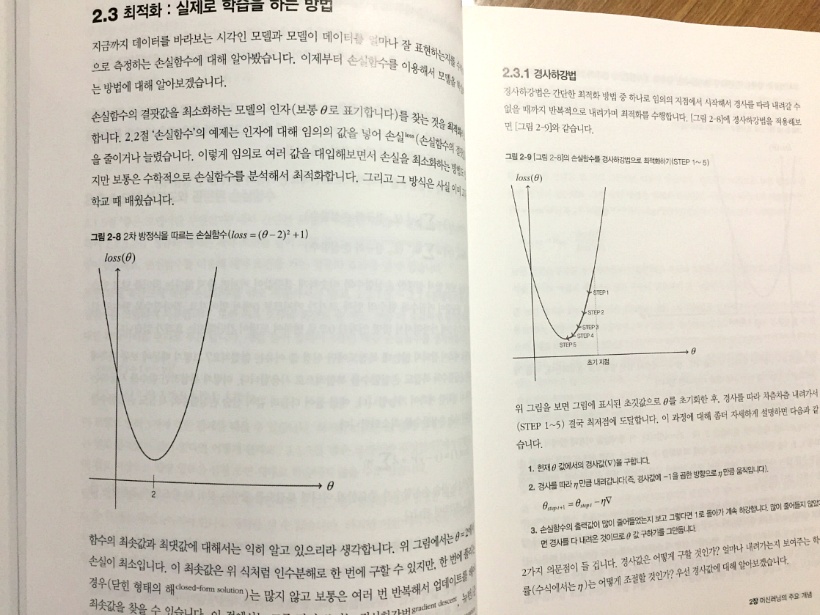
손실함수 (Loss Function) 의 정의는 “품질손실을 '제품이 다음 공정이나 소비자에게 출하된 뒤에 성능특성치의산포로 인하여 사회에 미치는 재정적인 손실' 로 정의할 때 이러한 손실이 화폐단위로 측정되고 수량화할수 있는 제품특성이나 관리방법을 평가할 수 있는 함수” 라고 대한상공회의소 홈페이지에 이렇게 나온다.
손실함수라는 개념은 새로운 것도 아닌데, 왜 나는 생전 처음보는 걸까? 그만큼 이 쪽하고는 인연이 없었다는 거다. 단어 설명은 최적화 쪽과관련되는 것 같은데, 단어 자체는 이 책에서 처음 본 인연이다. 이미봤었는데, 잊고 있었던 건가? 뭔가 비어있는 느낌… 판타지 속의 망각 저주, 존재 소멸 마법 같은 게 이런 느낌이려나?
이 책의 미덕은 아무리 생각해봐도 이론과 구현의 분리이다. 이론을직접 구현하는 쪽과 연결해서 보여주면 당장에 좋을 것 같기는 한데, 이론에서 이론으로 양상을 전개해가는면에 있어서는 흐름이 뚝뚝 끊기게 된다. 예전에는 이론 한 꼭지 보여주고, 그것을 어떻게 구현하는가에 대해서 코드 보여주고, 다음 것을 또그런 식으로 진행하는 식으로 써오곤 했다. 그리고, 대학교수님들 교재 같은 경우에는 순전히 이론과 수식만 들어가고 아예 구현부는 빠지든지 그리 정확하지도 않은Pseudo Code 2~3 개 정도 들어가고 땡. 이기도 했다.
각 장별 연관성이 다음과 같이 층위를 가지는 형태라서 몇 번 읽고 나서는 결국에 이렇게 다시 읽게 된다.
1 –2 – 3 – 9 – 8
4– 10
5– 11
6– 12
7– 13
4 – 5 – 6 – 7
각 주제별로 따로 잡고서 주제 1, 이론, 실습, 주제 2, 이론, 실습, … 의 순서로 엮인 책과 비교한다면 각각의 장단점이 있을 것이다. 그런데, 머신 러닝과 관련된 부분들이 너무 넓은 영역을 감당해야 한다. 그렇기때문에 작업자는 균형 잡힌 시각을 가지고 있다가, 나중에 써먹어야 할 때가 오면 해당 분야에 가장 적합한방법을 취사선택해서 가져올 수 있어야 할 것이다.
만약 Part 2 – 이론,Part 3 – 실전을 분리해놓지 않고 각 주제에 대해서 하나로 놓았을 때에도 나는 이것을 미덕이라고 했을까?
편집과 내용이 거기에 맞춰서 납득이 간다면 좋아했을 수 있지만, 지금이 책의 구성을 보고 난 다음이라 이론별-구현별 구분된 방식이 더 납득된다.
읽은 사람의 수준에 따라 편차가 있을 수도 있지만, 수식의 내용이나형식 등도 너무 번잡하지 않고, 너무 간단하지 않은 적당한 상태이다.
머신러닝의 내용에 대해서 알면 알수록,
“아, 사람은 덜 수고하고, 기계를 고생시키는 ‘노가다의 결정체’ 이구나.” 라는 생각을 하게 된다.
겸사겸사, 일에 대한, 비즈니스에대한 관점을 바꿔보게 된다는 덤도 있다.
나중에 내 사이트에서 여러 가지 라이브러리에 대해서 활용은 완전히 제쳐두고, 설치와연결 확인 여부에 대해서만 모아도 장사될 것 같다. 특히 리눅스 기반으로 된다는 것들을 윈도 기반에서어떻게 잘 연결시키나... 를 가지고…
여기에서는 바로 설치 확인된 것은 numpy 하나 뿐이고, 나머지는 설치 자체가 너무 힘들다.
아나콘다를 거부한 내 잘못인가?