옛 속담에 '구슬이 서 말이라도 꿰어야 보배'라는 말이 있는데, 인공지능 분야야 말로 이 말에 딱 맞는 예라 할 수 있다. CNN, GAN, LSTM, 미디어파이프 등 다양한 패턴이나 알고리즘에 대해 아무리 많이 알고 있다고 해도 이것들을 제대로 응용하지 못한다면, 아무 쓸모없기 때문이다.
하지만 그 응용 방법을 배울 기회가 적다는 근본적인 문제가 있다. 현재 인공지능 애플리케이션들이 많이 등장하고 있지만, 인공지능이 모든 프로그램에 적용되는 것이 아니다 보니, 인공지능 프로젝트에 참여할 기회가 많은 편은 아니다. 그리고 인공지능 분야는 경험에 따른 노하우 능력 차이가 워낙 커서 소위 초짜의 진입 장벽이 높다. 결국 해본 사람이 계속하게 되는 빈익빈 부익부 상태가 되고 있다.
실무 개발 기회가 적다고 암울해질 필요는 없다. 다행스럽게도 에마뉘엘 아메장의 저서, '머신러닝 파워드 애플리케이션'을 통해, 누구나 머신러닝 애플리케이션 프로젝트에 함께하며 얼마든지 노하우를 쌓을 수 있는 기회를 얻을 수 있다.
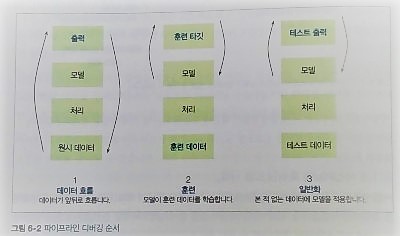
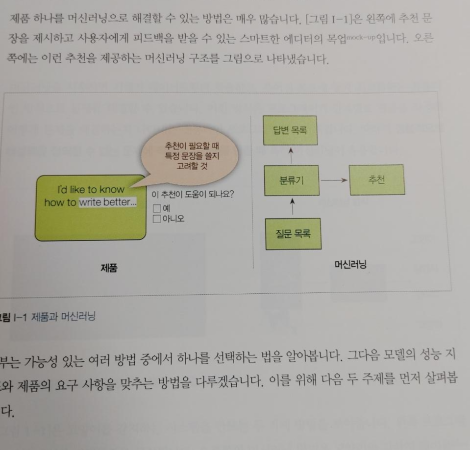
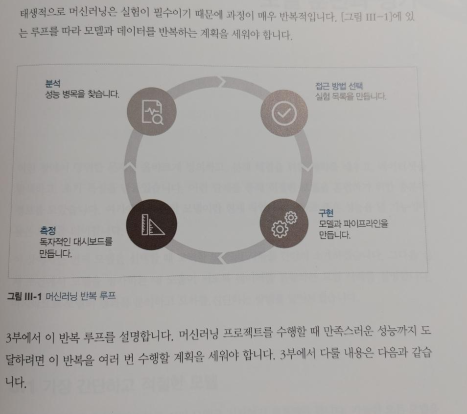
이 책은 머신러닝 프로그램 개발 처음부터 끝까지 모든 과정을 담았다. 사용자가 글을 더 잘 쓰도록 돕는 문장 추천하는 '머신러닝 에디터'를 개발하겠다는 단순한 아이디어 상태부터 시작해서, 이 개발 목표를 머신러닝 문제로 어떻게 표현할지 맨 먼저 검토해보고, 초기 계획에 맞춰, 가장 간단한 프로토타입을 만들어 본다. 그리고 데이터를 어떻게 구하고, 가공과 테스트는 어떻게 할지 점진적으로 구체화하며, 모델도 만들어 보고, 디버깅, 배포와 모니터링도 하며 머신러닝 애플리케이션을 완성한다.

전체적인 개발 과정을 보고 있으면, 저절로 애자일 개발방법론이 떠오른다. 머신러닝 애플리케이션 개발도 동일한 과정이 적용되는 것이다. 다만 기존에 프로그래밍 관련 책과는 다르게, '머신러닝 파워드 애플리케이션'에서는 파이썬 코드가 나오긴 하지만 코딩 자체 비중은 적다. (전체적인 코드 분석은 깃허브를 통해 독자가 스스로 해야 한다) 거의 대부분이 머신러닝 애플리케이션 실제 개발에 관련된 내용이다.
어떤 데이터가 유용한지, 데이터를 벡터화하고 군집 클러스터를 만들고 테스트하는 법, 학습 시에 발생할 수 있는 문제들, 어떤 사이트가 도움이 되고, 오픈 데이터, 오픈 소스 사용법, 방법에 따른 장점과 단점 등 기존의 인공지능 책에서 보지 못한 실무에 유용한 조언들을 가득 담고 있다. 심지어 저자의 경험 이야기만으론 부족했는지, 링크드인 외에 다양한 AI 전문 기업의 지인들의 견해와 노하우도 Q&A 방식으로 독자에게 알려주고 있다.

그리고 이것을 박해선 번역자도 제대로 한 몫 하며 거들고 있다. 곳곳에 옮긴이 주석을 달아서, 책 원본에 부족하거나, 추가로 설명하고자 하는 것들을 마구마구 담은 것이다. 역자의 이런 노고가 좀 더 완성도 높고, 독자에게 도움이 되는 '머신러닝 파워드 애플리케이션'을 만들었다 생각한다.
그런데 '머신러닝 파워드 애플리케이션'은 인공지능 이론을 가르쳐 주는 책이 아니다. 어디까지나 실무 개발 방법을 다룬 책이다. 그만큼 쉬운 책이 아닌 것이다. 적어도 중급서 이상으로 파이썬은 기본으로 알고 있어야 하고, 인공지능에 관련된 지식도 갖추고 있어야 한다. 책 자체의 설명은 어렵지 않으나, 일반적인 수준의 머신러닝 관련 내용은 자세한 설명 없이 이야기하고 있으므로 모르는 부분이 있다면, 주석을 참고해서 일일이 찾아 볼 필요가 있다. 인덱스까지 포함 303쪽의 그리 많아 보이지 않은 분량의 책이지만, 저자가 참고하라는 거, 주석, 내가 모르는 파트 같은 거 다 찾아가며 보면, 절대 작은 분량이 아니다.
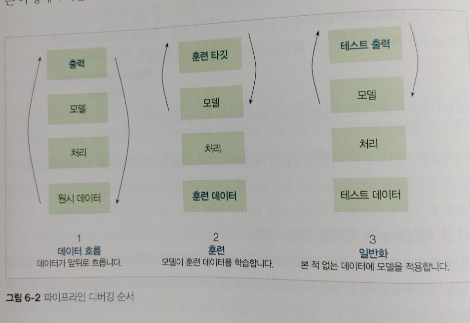
머신러닝 프로그램의 잘못된 결과는 데이터의 문제, 모델링의 문제, 학습의 문제 등에서 발생한다. 그렇기 때문에 저자는 아파트 임대 예약이나 환자 희귀 질병 예측 같은 예를 들어가며 발생할 수 있는 여러 조건과 문제 상황에 대해 말하고, 개선 또는 해결 방법을 말하고 있다.
인공지능 관련 책을 보면 다들 느끼겠지만, 인공지능은 1+1=2처럼 딱 떨어지는 게 아니고, 대충 2쯤 된다 그런 느낌을 받는다. 2가 정답이지만, 학습을 잘못하면, 3이나 1이 나와 잘못된 결과를 얻을 수 있는 것이다. (물론 연산을 인공지능으로 구현하진 않을 것이다. 그냥 예다.) 2라는 정답이 간단해 보여도, 인공지능에서는 이것을 제대로 도출하는 것이 개발자의 노하우이자, 능력인 것이다. 그러기 때문에 책에 나온 저자의 경험과 조언은 시행착오를 줄이고, 제대로 된 결과를 얻는데 많은 도움이 되는 것이다.
'머신러닝 파워드 애플리케이션'처럼 실무 측면에서 머신러닝을 다룬 책은 이번에 처음 접한다. 실제 머신러닝 애플리케이션을 어떻게 개발하는지 확실히 엿보고 배울 수 있는 책이었다. 머신러닝 실무를 배운다는 생각으로 봐도 좋겠지만, 책 구성 상, 저자와 함께 프로그램을 한 단계 한 단계 올라가며 만들어 본다는 느낌으로 보면 더 현실감을 느끼며 볼 수 있을 거 같다. 이 책이 모든 머신러닝 작업에 표준이 되지는 않겠지만, 적어도 개인적으로는 머신러닝 프로그램을 개발하게 된다면, PC 옆에 두고, 자주 보며, 참고할 거 같다.