IT/모바일
✅알고리즘이란?
알고리즘(Algorithm)이란 어떤 문제를 해결하기 위해 밟아 나가는 연속적인 단계를 말합니다. 예를 들어, 계란 후라이를 만드는 알고리즘이라면 우선 계란 하나를 깨서 프라이팬에 올리고 잘 익힌 후 팬에서 꺼내는 일련의 과정이 되겠지요.
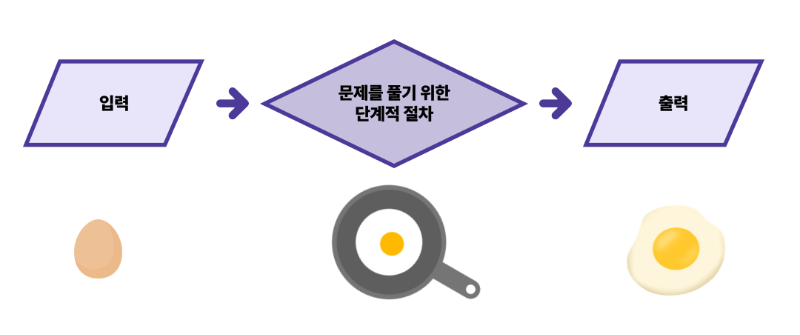
개발자는 보통 알고리즘을 작성하고, 어떤 자료구조를 그 알고리즘에 적용할지 고민하면서 대부분의 시간을 보냅니다. 그렇기 때문에 개발자에게 어떤 알고리즘이 더 좋은지를 판단하는 것은 매우 중요한 능력입니다. 어떤 알고리즘을 선택해야 하는지 판단할 수 없다면 효율적인 개발자가 될 수 없습니다.
알고리즘은 컴퓨터 과학의 기본 개념이지만, 공식적으로 정의되지는 않았습니다. 알고리즘에는 여러 가지 정의가 있는데, 그중 가장 잘 알려진 것은 도널드 커누스(Donald Knuth)의 정의입니다. 커누스는 알고리즘을 ‘입력을 기반으로 출력을 생성하는 명확하고, 효율적이며 유한한 프로세스’라고 정의했습니다.
- 명확함(Definiteness): 각 단계가 명료하고 간결하며 모호하지 않음
- 효율성(Effectiveness): 각 동작이 문제 해결에 기여함
- 유한함(Finiteness): 알고리즘이 유한한 단계를 거친 후 종료됨
여기에 정확성(Correctness)을 추가하는 경우가 많습니다. 알고리즘은 입력이 같으면 항상 같은 결과를 내야 하며, 이 결과가 알고리즘이 해결하는 문제의 정확한 답이어야 한다는 것입니다.
대부분의 알고리즘이 이 요건을 만족하지만 몇 가지 중요한 예외가 있습니다. 예를 들어, 난수 발생기(Random Number Generator)를 만든다면 누군가 입력을 보고 결과를 짐작할 수 없는 무작위성을 목표로 해야 합니다. 또한 데이터 과학의 알고리즘 중에는 정확성을 엄격히 따지지 않는 것도 많습니다. 추정 자체가 불확실하다고 알려진 알고리즘이라면 근삿값을 찾는 것만으로도 충분합니다.
하지만 이와 같은 몇 가지 예외를 제외한다면 알고리즘은 앞에서 말한 세 가지 요건을 항상 만족해야 합니다. 계란 후라이를 만드는 알고리즘을 작성했는데 때때로 오믈렛이나 삶은 계란이 만들어지면 안 되니까요.
✅최선의 알고리즘은 어떻게 찾아야 할까?
한 가지 문제를 해결할 때 여러 가지 알고리즘을 사용할 수 있을 때가 많습니다. 리스트를 정렬하는 방법이 다양한 것처럼 말입니다. 여러 가지 알고리즘으로 문제를 풀 수 있다면 최선의 알고리즘은 어떻게 찾아야 할까요? 가장 단순한 것? 가장 빠른 것? 가장 짧은 것? 아니면 다른 기준이 있을까요?
실행 시간은 알고리즘을 평가하는 기준 중 하나입니다. 알고리즘의 실행 시간은 파이썬 같은 프로그래밍 언어로 만든 알고리즘을 컴퓨터가 실행하는 데 걸리는 시간을 말합니다. 다음은 1부터 5까지의 숫자를 출력하는 파이썬 알고리즘의 예입니다.

다음과 같이 파이썬에 내장된 time 모듈을 사용하여 이 알고리즘의 실행 시간을 측정할 수 있습니다.
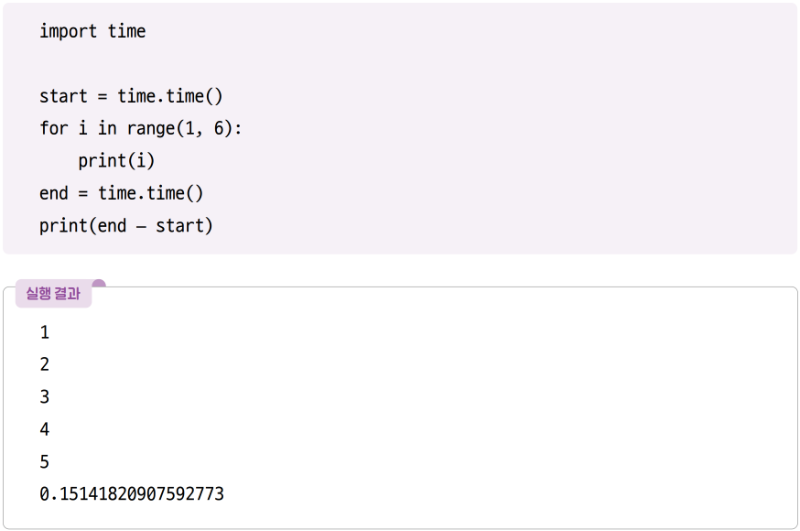
프로그램을 실행하면 1부터 5까지의 숫자를 출력하고, 여기에 소요된 시간도 출력합니다. 0.15초가 걸렸습니다. 프로그램을 다시 실행해도 같은 결과가 나올까요?

프로그램을 두 번째로 실행하면 실행 시간이 달라집니다. 다시 프로그램을 실행한다면 실행 시간은 또 달라지게 됩니다. 프로그램을 실행하는 순간 컴퓨터가 사용할 수 있는 CPU의 자원이 매번 다르고, 이 자원이 프로그램의 실행 시간에 영향을 미치므로 알고리즘의 실행 시간도 매번 달라집니다.
또한 알고리즘의 실행 시간은 컴퓨터의 성능에 따라 다릅니다. 처리 능력이 떨어지는 컴퓨터에서 실행하면 그만큼 느릴 것이고, 성능이 좋은 컴퓨터에서 실행하면 그만큼 빠를 것입니다. 프로그램의 실행 시간은 사용하는 프로그래밍 언어에 따라서도 달라집니다. 예를 들어 C 언어는 파이썬보다 실행 속도가 더 빠르기 때문에 같은 프로그램이라도 C 언어로 작성하면 실행 시간이 짧아집니다.
알고리즘을 비교할 때 알고리즘의 실행 시간은 컴퓨터 CPU의 자원이나 프로그래밍 언어와 같은 여러 가지 변수의 영향을 받으므로 효과적인 기준이 될 수 없습니다. 이러한 이유로 컴퓨터 과학자들은 알고리즘에 필요한 단계를 살펴보면서 알고리즘을 비교합니다. 두 개 이상의 알고리즘을 비교해야 한다면 프로그래밍 언어나 컴퓨터의 사양과 같은 변수는 제외하고, 알고리즘에 필요한 단계를 수식으로 비교합니다.
예제로 확인해 보겠습니다. 다음 코드는 앞에서 1부터 5까지의 숫자를 셌던 프로그램입니다.

이 프로그램은 다섯 번의 루프를 실행하면서 i를 출력하므로 총 다섯 번의 단계를 거칩니다. 다음과 같이 이 알고리즘에 필요한 단계는 f(n)으로 표현할 수 있습니다.

프로그램이 복잡해지면 f(n)도 바뀝니다. 이번에는 출력되는 숫자의 합을 구해보겠습니다.

알고리즘은 이제 열 한 번의 단계를 거쳐야 완료됩니다. count 변수에 0을 할당하고, 1부터 5까지의 숫자를 다섯 번 출력합니다. 그리고 그때마다 출력된 숫자의 합을 구하므로 1 + 5 + 5 = 11단계가 됩니다.
f(n)은 다음과 같이 바뀌었습니다.

숫자 6을 변수 n으로 바꾸면 어떻게 될까요?


f(n)은 다음과 같이 바뀝니다.

이제 알고리즘의 단계는 n값에 의해 좌우됩니다. f(n)의1은 첫 번째 단계인 count=0에 해당하며, 그 다음에는 숫자를 출력하고 합을 구하는 2n만큼의 단계가 필요합니다. 예를 들어 n이 5라면 f(n)=1+2×5입니다. 컴퓨터 과학자는 알고리즘의 단계를 나타내는 f(n) 의 변수 n을 데이터의 크기라고 부릅니다. 데이터의 크기가 n인 문제를 푸는 데 필요한 시간이 1+2n이라고 할 수 있으며, 수학적으로는 T(n)=1+2n이라고 표기합니다.
하지만 알고리즘에 필요한 단계를 항상 정확하게 셀 수 없기 때문에 알고리즘의 단계를 수식으로 표현하는 것이 아주 효과적인 방법이라고 할 수는 없습니다. 예를 들어 알고리즘에 조건문이 아주 많다면 그중 어떤 부분이 실행될지 미리 알 수 없을뿐더러 다행스럽게도 우리는 알고리즘의 단계를 정확하게 알 필요도 없습니다.
중요한 것은 n의 변화에 따른 알고리즘 성능의 변화를 예상하는 것입니다. 데이터 세트가 작을 때는 어떤 알고리즘이든 별 문제가 없지만 데이터 세트가 아주 클 때는 비효율적인 알고리즘이 곧 재앙이 될 수 있습니다. 반대로 가장 비효율적인 알고리즘이라 하더라도 데이터의 크기가 1이라면 전혀 문제가 되지 않겠지만, 실제로 데이터의 크기가 1인 경우는 거의 없습니다. 십만, 백만 또는 그 이상일 가능성이 더 크죠.
알고리즘이 정확하게 몇 단계를 거치는지가 아니라, 데이터의 크기가 늘어날 때마다 알고리즘의 단계가 얼마나 늘어나는지를 대략적으로 파악하는 것이 가장 중요합니다. n이 커지면서 f(n)의 한 부분이 급격하게 커지면 그 외에 다른 부분을 비교하는 것이 무의미할 수 있습니다.

이 프로그램의 어떤 부분을 봐야 알고리즘에 몇 단계가 필요한지 판단할 수 있을까요? 루프 1과 루프 2 모두 중요한 변수라고 생각할 수도 있습니다. 어쨌든 n이 10,000 정도가 된다면 컴퓨터는 두 루프 모두에서 아주 많은 숫자를 출력할 테니까요. 하지만 알고리즘의 효율성을 따질 때 루프 1은 무시해도 될 수준입니다.
이를 이해하기 위해서는 n이 커질 때 어떤 일이 일어나는지 살펴봐야 합니다. 다음은 이 알고리즘의 단계를 나타내는 수식 T(n)입니다.

for 함수가 두 번 중첩된 루프를 n번 반복하면, 이는 n의 제곱인 n**2로 나타냅니다. 예를 들어 n이 10이라면 10을 10번 반복해야 하므로 10**2가 되는 것입니다. 마찬가지로 for 함수가 세 번 중첩된 루프는 n**3으로 나타낼 수 있습니다. 만약 T(n)에서 n이 10이라면 루프 1에서는 10단계를 거치고, 루프 2에서는 10의 세제곱인 1,000단계를 거칩니다. n이 1,000이라면 루프 1에서는 1,000단계, 루프 2에서는 1,000의 세제곱인 10억 단계를 거치게 되겠죠.
n이 커지면 커질수록 알고리즘의 두 번째 루프가 너무 빨리 커지기 때문에 첫 번째 루프를 따지는 것이 무의미해집니다. 예를 들어 이 알고리즘이 1억 개의 데이터를 대상으로 작동한다면 두 번째 루프의 단계가 너무 크기 때문에 첫 번째 루프가 몇 단계를 거치든 신경 쓰지 않게 될 것입니다. 데이터가 1억 개라면 두 번째 루프의 단계가 1 뒤에 0이 24개나 있는 숫자가 되므로 이런 상황에서 첫 번째 루프의 단계가 1억 번이라는 것은 아무 의미가 없습니다.
따라서 알고리즘의 효율에서 가장 중요한 부분은 ‘n이 커질 때 알고리즘의 단계가 얼마만큼 증가하는가’이므로, 이것을 잘 나타내는 빅 O 표기법을 사용합니다. 빅 O 표기법(Big O notation)은 n이 커짐에 따라 알고리즘의 시간 또는 공간의 요건이 얼마나 커지는지를 나타내는 수학적 표기법을 말합니다.
빅 O 표기법은 T(n)에서 규모 함수를 도출하는데, 규모(Order of Magnitude)란 차이가 아주 큰 등급 체계에서의 크기 차이를 뜻합니다. 규모 함수에서는 알고리즘의 실행 단계를 나타내는 T(n)에서 수식을 지배하는 부분만 남기고, 나머지는 모두 무시합니다. 즉, T(n)에서 가장 지배적인 부분이 빅 O 표기법에서 도출한 알고리즘의 규모가 되는 것입니다.
다음은 빅 O 표기법에서 가장 널리 사용되는 규모 함수들을 최선(가장 효율적)에서 최악(가장 비효율적)의 순서로 나열한 것입니다. 각각의 규모 함수는 알고리즘의 시간 복잡도를 나타냅니다. 시간 복잡도(Time Complexity)란 n이 커짐에 따라 알고리즘이 실행되고 완료될 때까지 필요한 단계를 말합니다.

이어서 읽기 ► [알고리즘] 시간 복잡도와 Big O 표기법
위 콘텐츠는 『나의 첫 알고리즘+자료구조 with 파이썬』의 내용을 바탕으로 작성되었습니다.

이전 글 : 모두를 놀라게 할 꼬마 링크의 새로운 등장
다음 글 : 오라일리 멸종위기 동물에 대해 알아보자
![[알고리즘 + 자료구조 = 프로그램] 자료구조의 개념과 종류](/data/cms/CMS2832062046_thumb.png)
![[알고리즘] 시간 복잡도와 Big O 표기법](/data/cms/CMS7965376216_thumb.png)

최신 콘텐츠